এখন লিনাক্সের টার্মিনাল কনসোলে এর আইকনভ ইউটিলিটি দেখে নেওয়া যাক। সুতরাং, আমরা আমাদের টার্মিনাল স্ক্রিনে সমস্ত পরিচিত এবং সর্বাধিক ব্যবহৃত কোডেড অক্ষর সেটগুলি প্রদর্শন করার জন্য '-l' পতাকা সহ 'আইকনভ' নির্দেশনা কার্যকর করছি। এটি তাদের উপনাম সহ কোডেড অক্ষর সেটগুলি প্রদর্শন করবে। আপনি একটু নিচে স্ক্রোল করার পরে কোডেড অক্ষর সেটের একটি দীর্ঘ তালিকা দেখতে পারেন।
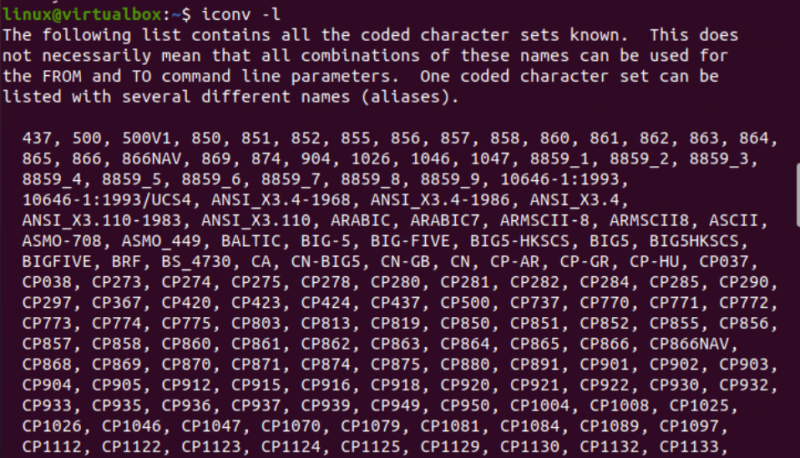
এখন, লিনাক্সে iconv কমান্ড বাস্তবায়নের সাথে শুরু করার সময়। প্রথমত, এক ধরনের ফাইলকে অন্য ধরনের ফাইলে রূপান্তর করতে আমাদের সিস্টেমে বিভিন্ন ধরনের ফাইলের প্রয়োজন। এইভাবে, আমরা তিনটি ভিন্ন ফাইল, যেমন, জাভা টাইপ, সি টাইপ এবং টেক্সট টাইপ তৈরি করতে কনসোল টার্মিনালে 'টাচ' কোয়েরি ব্যবহার করছি। বর্তমান ডিরেক্টরি বিষয়বস্তু তালিকা, আপনি এটি নতুন উত্পন্ন ফাইল পাবেন.
এর পরে, আমরা প্রতিটি ফাইলের নামের সাথে 'ফাইল' ক্যোয়ারী ব্যবহার করে প্রতিটি ফাইলের ধরন আলাদাভাবে দেখব। প্রতিটি ফাইলের জন্য আলাদাভাবে কোডিং অক্ষর সেটের ধরন প্রদর্শন করতে এই ক্যোয়ারীটির জন্য '-I' বিকল্পের প্রয়োজন। আপনি যদি '-I' বিকল্পটি ব্যবহার করতে ভুলে যান তবে পরিবর্তে '—mime' পতাকাটি ব্যবহার করুন৷ উভয় '-I' এবং '-mime' পতাকা একই কাজ করে।
এখন, 'txt' টাইপ ফাইলের জন্য 'ফাইল' নির্দেশনা কার্যকর করার পরে, আমরা 'US-ASCII' অক্ষর টাইপ এনকোডিং পেয়েছি। জাভা এবং সি ফাইলগুলির জন্য একই নির্দেশনা ব্যবহার করার সময়, এটি দেখায় যে উভয় ফাইলেই 'বাইনারী' অক্ষর টাইপ এনকোডিং রয়েছে। সেই সাথে, এই নির্দেশটি দেখায় যে এই তিনটি ফাইলই খালি।
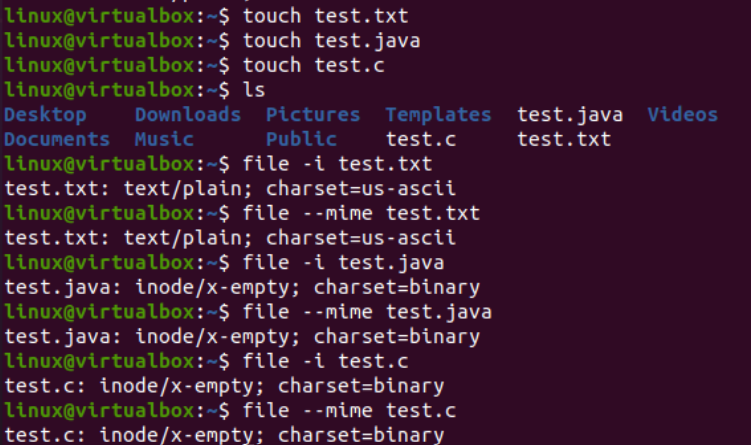
এখন, আমরা একটি নির্দিষ্ট অক্ষর সেট এনকোডিং ফাইলকে অন্য অক্ষর সেট এনকোডিং-এ রূপান্তর করতে কনসোলে iconv নির্দেশের ব্যবহার চিত্রিত করব। তার আগে, আমাদের ফাইলগুলিতে কিছু কোড বা ডেটা যোগ করতে হবে। তাই, আমরা “text.java” ফাইলের মধ্যে জাভা কোড, “text.c” ফাইলের মধ্যে C কোড এবং “test.txt” ফাইলের মধ্যে টেক্সট ডেটা যোগ করেছি। নীচে উপস্থাপিত হিসাবে তিনটি ফাইলের বিষয়বস্তু প্রদর্শন করতে এখানে ক্যাট কোয়েরি ব্যবহার করা হয়েছিল:
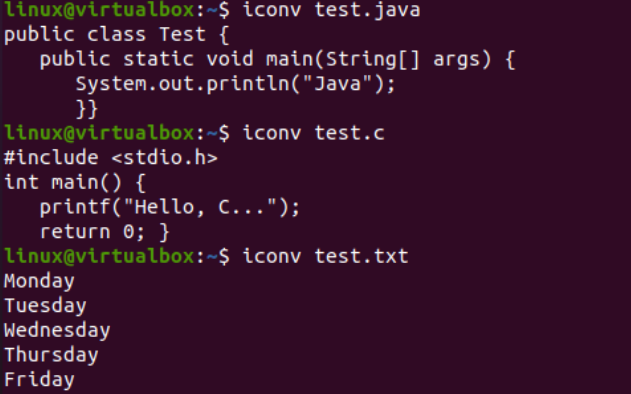
এখন যেহেতু আমরা সফলভাবে ডেটা যোগ করেছি, আমরা আবার এই ফাইলগুলির অক্ষর সেট এনকোডিং দেখতে পাব। সুতরাং, আমরা “-I” পতাকা এবং ফাইলের নাম, যেমন, test.txt, test.java এবং test.c সহ শেলের মধ্যে একই ফাইল নির্দেশনা চেষ্টা করেছি। তিনটি ফাইলের জন্য আলাদাভাবে এই তিনটি নির্দেশনা চালানোর ফলে দেখা যায় যে জাভা এবং সি ফাইলের জন্য ক্যারেক্টার সেট এনকোডিং আপডেট করা হয়েছে যখন টেক্সট ফাইলের জন্য একই থাকে, যেমন, US-ASCII। জাভা এবং সি ফাইলের এনকোডিং আগে ছিল 'বাইনারী'; এখন, এটি 'US-ASCII'। এছাড়াও, এটি দেখায় যে টেক্সট ফাইলটিতে প্লেইন টেক্সট ডেটা থাকে যখন অন্য দুটি কোড ফাইলে স্ক্রিপ্টগুলি সামগ্রী হিসাবে থাকে।

এই নিবন্ধটির জন্য প্রয়োজনীয় প্রকৃত কাজ সম্পাদন করার সময় এসেছে, যেমন, শেলের iconv কমান্ড ব্যবহার করে একটি এনকোডিংকে অন্যটিতে রূপান্তর করুন। এইভাবে, আমরা শেল টার্মিনালের মধ্যে 'sudo' সুবিধা সহ 'iconv' নির্দেশনা ব্যবহার করছি। এই কমান্ডটি নেয় '-f' বিকল্পটি 'from' এর জন্য, এবং '-t' বিকল্পটি 'to', অর্থাৎ, একটি এনকোডিং থেকে অন্যটিতে।
'-f' বিকল্পের পরে, আপনাকে আপনার ফাইলে ইতিমধ্যেই রয়েছে, যেমন US-ASCII এনকোডিং উল্লেখ করতে হবে। '-t' বিকল্পের পরে, আপনি যে এনকোডিংটিকে পুরানো এনকোডিং দিয়ে প্রতিস্থাপন করতে চান তা নির্দিষ্ট করতে হবে, যেমন, ইউনিকোড৷ বস্তুর ইমেজ তৈরি করার জন্য আপনাকে –o বিকল্পের সাহায্যে উৎস হিসেবে ব্যবহৃত একটি ফাইলের নাম উল্লেখ করতে হবে। অবজেক্ট ইমেজ অন্য ফাইল হবে, যেমন, 'new.c', একই ধরনের কিন্তু নতুন এনকোডিং এবং একই ডেটা সহ।
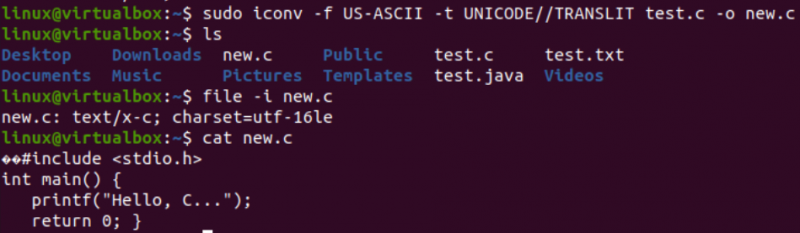
নিম্নলিখিত নির্দেশনাটি কার্যকর করার পরে, আপনি একই ডিরেক্টরিতে একটি নতুন ফাইল পাবেন, অর্থাৎ, 'ls' ক্যোয়ারী অনুসারে। এখন, আমরা iconv নির্দেশ ব্যবহার করে তৈরি করা একটি নতুন ফাইলের অক্ষর সেট এনকোডিং পরীক্ষা করব। আমরা আবার 'ফাইল' নির্দেশনা ব্যবহার করব '-I' বিকল্প এবং নতুন ফাইলের নাম, যেমন, new.c.
আপনি দেখতে পাবেন যে এই নতুন ফাইলের জন্য অক্ষর সেটটি একটি পুরানো ফাইলের অক্ষর সেট থেকে ভিন্ন হয়েছে, যেমন, UTF-16LE অক্ষর সেট। কারণ আমরা আমাদের new.c ফাইলের জন্য iconv নির্দেশ ব্যবহার করে US-ASCII এনকোডিংকে UNICODE এনকোডিং-এ অনুবাদ করেছি। 'বিড়াল' ক্যোয়ারী ফাইলের মধ্যে একই C কোড প্রদর্শন করেছে কিন্তু কিছু ইউনিকোড অক্ষর দিয়ে শুরু হয়েছে, যেমনটি ইতিমধ্যে উপস্থাপিত হয়েছে।
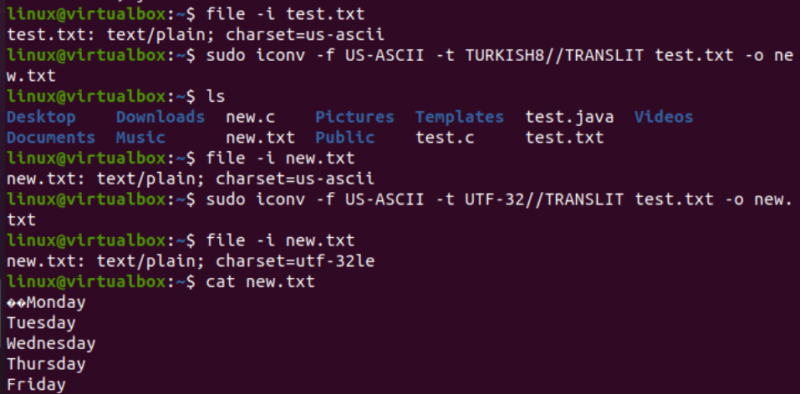
একইভাবে, আমরা test.txt টেক্সট ফাইলের এনকোডিং পরিবর্তন করব। ফাইলের নির্দেশ দেখায় যে এটিতে একটি US-ASCII অক্ষর সেট এনকোডিং রয়েছে। test.txt ফাইলের এনকোডিং US-ASCII থেকে TURKISH8 এ রূপান্তর করতে iconv কমান্ডটি একই বিন্যাসে ব্যবহার করা হয়েছে। আপনি দেখতে পাবেন যে এটি US-ASCII কে তুর্কিতে পরিবর্তন করে না।
এর পরে, আমরা একই ফাইলের জন্য US-ASCII থেকে UTF-32 অক্ষর সেট এনকোডিং কভার করতে একই কমান্ড ব্যবহার করেছি। এই সময়, এটা কাজ করে. এটি হল কারণ কখনও কখনও একটি এনকোডিং সেট অন্যটিতে রূপান্তর করতে সমস্যা হতে পারে বা অন্য এনকোডিং এটি সমর্থন নাও করতে পারে৷
উপসংহার
এই নিবন্ধে আলোচনা করা হয়েছে কিভাবে iconv Linux নির্দেশাবলী ব্যবহার করে তাদের উপনাম ব্যবহার করে একটি এনকোডিং অক্ষর সেটকে অন্যটিতে রূপান্তর করতে হয়। এই পদ্ধতিতে, আমাদের বিভিন্ন ধরণের কিছু ফাইল তৈরি করতে হয়েছিল।