ডাটা-কেন্দ্রিক পাইথন প্যাকেজগুলির দুর্দান্ত ইকোসিস্টেমের কারণে 'পান্ডাস' ডেটা বিশ্লেষণ করার জন্য একটি দুর্দান্ত ভাষা। এটি উভয় কারণের বিশ্লেষণ এবং আমদানি সহজ করে তোলে। আদর্শ বিচ্যুতি হল গড় থেকে উদ্ভূত একটি 'সাধারণ' বিচ্যুতি। এটি প্রচুর ব্যবহার করা হয়, কারণ এটি ডেটাফ্রেমের পরিমাপের মূল ইউনিটগুলি প্রদান করে। স্ট্যান্ডার্ড ডেভিয়েশন গণনার জন্য পান্ডারা std() ব্যবহার করেছে। প্রদত্ত মানগুলি থেকে স্ট্যান্ডার্ড বিচ্যুতি গণনা করা যেতে পারে যা একটি সারি বা কলাম আকারে ডেটাফ্রেমে থাকতে পারে। পান্ডাস স্ট্যান্ডার্ড বিচ্যুতি ব্যবহার করা হয় এমন সমস্ত সম্ভাব্য উপায় আমরা বাস্তবায়ন করব। কোডটি বাস্তবায়নের জন্য, আমরা 'স্পাইডার' টুলটি ব্যবহার করব কারণ এটি একটি পাইথন-বান্ধব পরিবেশে লেখা হয়েছে।'
বাক্য গঠন
'df.std ( ) '
নিম্নলিখিত সিনট্যাক্সটি ডেটাফ্রেমে আদর্শ বিচ্যুতি গণনা করার জন্য ব্যবহৃত হয়। ডেটাফ্রেমের 'df' হল 'ডেটাফ্রেম' এর সংক্ষিপ্ত রূপ। প্রমিত বিচ্যুতি কি করে? এটি প্রয়োজনীয় ডেটা কতটা বর্ধিত তা পরিমাপ করে। উচ্চ মান যত বেশি প্রসারিত হবে, মান বিচ্যুতি তত বেশি হবে।
প্রত্যাবর্তন
প্রয়োজনের উপর ভিত্তি করে লেভেল নির্দিষ্ট করা হলে পান্ডাস স্ট্যান্ডার্ড ডেভিয়েশন ডেটাফ্রেম ফেরত দেয়।
মনে রাখবেন যে 'std()' ফাংশনটি স্বয়ংক্রিয়ভাবে 'df'-এর 'NaN' মানগুলিকে উপেক্ষা করবে যখন পান্ডাস স্ট্যান্ডার্ড বিচ্যুতি গণনা করবে। 'NaN' কে 'সংখ্যা নয়' হিসাবে ব্যাখ্যা করা যেতে পারে যার অর্থ হল একটি নির্দিষ্টের জন্য কোন মান নির্ধারিত নেই।
নিম্নলিখিত পদ্ধতিগুলি যা পান্ডা স্ট্যান্ডার্ড বিচ্যুতির উদাহরণ সহ কার্যকর করা হবে:
-
- একটি একক কলামে পান্ডাস মান বিচ্যুতি গণনা।
- একাধিক কলামে পান্ডাস স্ট্যান্ডার্ড বিচ্যুতি গণনা।
- সমস্ত সাংখ্যিক কলামের পান্ডাস স্ট্যান্ডার্ড বিচ্যুতি গণনা।
- অক্ষ = 1 ব্যবহার করে পান্ডাস স্ট্যান্ডার্ড বিচ্যুতি।
- অক্ষ = 0 ব্যবহার করে পান্ডাস স্ট্যান্ডার্ড বিচ্যুতি।
পান্ডাসে স্ট্যান্ডার্ড ডেভিয়েশন গণনার জন্য ডেটাফ্রেম তৈরি করা
প্রথমে, 'স্পাইডার' সফ্টওয়্যারটি খুলুন। এখন pd হিসাবে পান্ডাস লাইব্রেরি আমদানি করুন। আমরা একটি ডেটাফ্রেম তৈরি করব যেখানে একটি স্কোরবোর্ড থাকবে যার মধ্যে 'x', 'y' এবং 'z' শব্দ থাকবে এবং তাদের পয়েন্টগুলি '22', '10', '11', '16', '12', '45' ”, “36”, এবং “40”। আমাদের কাছে “8”, “9”, “13”, “7”, “22”, “24”, “4” এবং “6” হিসাবে তাদের সহায়তার মান রয়েছে, এছাড়াও রিবাউন্ডের মান “17”, “ 14”, “3”, 5”, “9”, “8”, “7” এবং “4”।
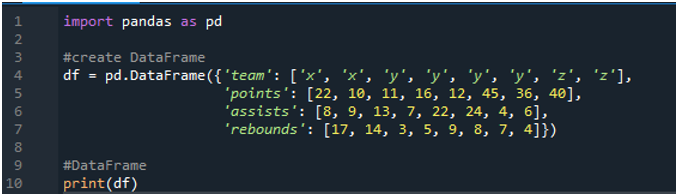
প্রদর্শনগুলি কোডে নির্ধারিত মান অনুসারে তৈরি ডেটাফ্রেম দেখায়:

উদাহরণ # 01: একটি একক কলামে পান্ডাস স্ট্যান্ডার্ড বিচ্যুতি গণনা
এই উদাহরণে, আমরা পান্ডাস ডেটাফ্রেমের একটি একক কলামের আদর্শ বিচ্যুতি গণনা করব। ডেটাফ্রেমে টিমের মান 'u', 'v' এবং 'b' হিসাবে রয়েছে তাদের পয়েন্টগুলি '44', '33', '22', '44', '45', '88', '96' ' এবং '78'। সহায়তার মান হল “7”,”8”, “9”, “10”, “11”, “14”, “18”, এবং “17” এছাড়াও রিবাউন্ডের মান “11”, “ 9”, “8”, “7”, “6”, “5”, “4”, এবং “3”। একক কলাম স্ট্যান্ডার্ড বিচ্যুতি গণনা করতে ডেটাফ্রেম থেকে কলাম 'পয়েন্ট' নির্বাচন করা হয়।
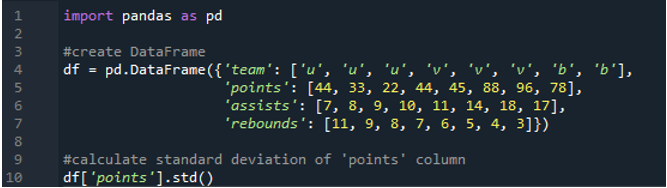
আউটপুট কলাম 'পয়েন্ট' এর গণনা করা আদর্শ বিচ্যুতি দেখায়:

উদাহরণ # 02: একাধিক কলামে পান্ডাস স্ট্যান্ডার্ড ডেভিয়েশন গণনা
এই উদাহরণে, আমরা একাধিক কলামে পান্ডাস স্ট্যান্ডার্ড বিচ্যুতি গণনা চালাব। এই ডাটাফ্রেমে, ডাটা আবার স্পোর্টস স্কোরবোর্ডের হয় যেখানে দলের মান “n”, “w” এবং “t” এবং স্কোর “33”, “22”, “66”, “55”, '44', '88', '99', এবং '77'। “9”, “7”, “8”, “11”, “16”, “14”, “12” এবং “13” এবং “5”, “8”, “1”, “এর মতো রিবাউন্ড করে 2”, “3”, “4”, “6”, এবং “7”। এখানে আমরা ডেটাফ্রেমে প্রয়োগ করা ফাংশন std() ব্যবহার করে 'পয়েন্ট' এবং 'রিবাউন্ডস' দুটি কলামের আদর্শ বিচ্যুতি গণনা করব।
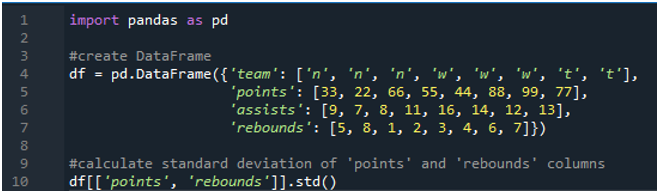
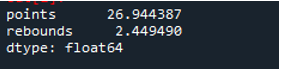
আমরা যেমন দেখি, আউটপুট দেখায় যে স্ট্যান্ডার্ড বিচ্যুতি যথাক্রমে পয়েন্ট কলামে 26.944387 এবং রিবাউন্ড কলামে 2.449490 হিসাবে এসেছে।
উদাহরণ # 03: সমস্ত সাংখ্যিক কলামের পান্ডাস স্ট্যান্ডার্ড ডেভিয়েশন গণনা
এখন আমরা শিখেছি কিভাবে একক এবং একাধিক সারির আদর্শ বিচ্যুতি গণনা করতে হয়। আমরা যদি ডেটাফ্রেমের সমস্ত কলামের নাম নির্দিষ্ট করতে না চাই এবং পুরো ডেটাফ্রেমটি গণনা করতে চাই তবে কী হবে? ফলাফলে সম্পূর্ণ ডেটাফ্রেমের গণনার জন্য পান্ডাস স্ট্যান্ডার্ড বিচ্যুতির একটি সাধারণ ফাংশন বাস্তবায়নের মাধ্যমে এটি সম্ভব। এখানে ডেটাফ্রেমে স্কোরিং মান '33', '36', '79', '78', '58', '55' সহ 'l', 'm' এবং 'o' রয়েছে এবং দুটি দল একই স্কোর করে। সেটা হল '25'। সহায়তাগুলি হল “1”, “2”, “3”, “4”, “6”, “9”, “5” এবং “7” এবং তাদের রিবাউন্ড হিসাবে “14”, “10”, “2” , “5”, “8”, “3”, “6” এবং “9”। আমরা pandas “std()” ফাংশন ব্যবহার করে ডেটাফ্রেমে পান্ডা দ্বারা সমস্ত স্ট্যান্ডার্ড কলামের বিচ্যুতি গণনা করতে পারি।
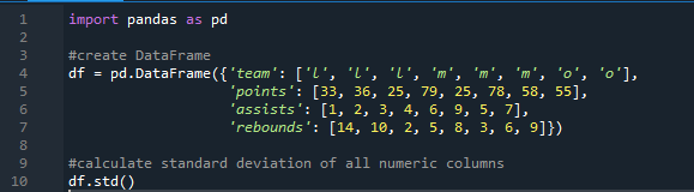
ডিসপ্লেতে নীচে দেখানো সম্পূর্ণ 'df' এর গণনাকৃত মানক বিচ্যুতি রয়েছে; আমরা এটাও লক্ষ্য করতে পারি যে পান্ডারা প্রথম কলামের স্ট্যান্ডার্ড বিচ্যুতি গণনা করেনি, যা হল 'টিম', কারণ এটি একটি সংখ্যাসূচক কলাম নয়।
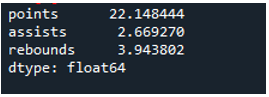
উদাহরণ # 04: অক্ষ = 0 ব্যবহার করে পান্ডাস স্ট্যান্ডার্ড বিচ্যুতি
এই উদাহরণে, ডেটাফ্রেমে আরও ডেটা সহ 'g', 'h', এবং 'k' হিসাবে খেলার দল রয়েছে৷ এখানে, আমরা অক্ষটিকে '0' হিসাবে ব্যবহার করে মানক বিচ্যুতি গণনা করব, পান্ডাস স্ট্যান্ডার্ড বিচ্যুতিতে ব্যবহৃত একটি প্যারামিটার। এই আর্গুমেন্ট ডেটাফ্রেমের কলাম অনুযায়ী স্ট্যান্ডার্ড বিচ্যুতি গণনা করে।
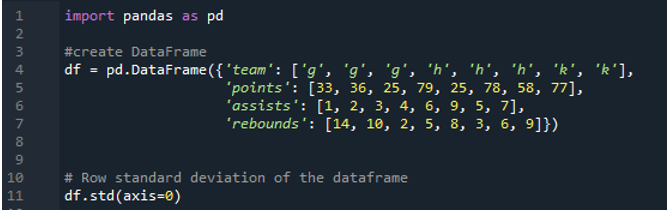
নিম্নলিখিত আউটপুট গণনা করা স্ট্যান্ডার্ড বিচ্যুতির কলামে ফলাফল প্রদর্শন করে। পয়েন্ট কলামে '24.0313062' হিসাবে গণনা করা স্ট্যান্ডার্ড বিচ্যুতি রয়েছে, সহায়তা কলামে '2.669270' হিসাবে গণনা করা স্ট্যান্ডার্ড বিচ্যুতি রয়েছে এবং রিবাউন্ড কলামের গণনাকৃত স্ট্যান্ডার্ড বিচ্যুতি '3.943802' হিসাবে দেখানো হয়েছে।
উদাহরণ # 05: অক্ষ = 1 ব্যবহার করে পান্ডাস স্ট্যান্ডার্ড বিচ্যুতি
এখানে আমরা পান্ডাতে স্ট্যান্ডার্ড বিচ্যুতি গণনা করতে '1' হিসাবে নির্ধারিত অক্ষ প্যারামিটার ব্যবহার করব। অক্ষ '1' কি পার্থক্য করতে পারে? '1' অক্ষ যুক্তিটি ডেটাফ্রেমের সাংখ্যিক মানের সারি-ভিত্তিক স্ট্যান্ডার্ড বিচ্যুতি গণনা করে। ডেটাফ্রেমে 's', 'd' এবং 'e' হিসাবে তিনটি দল রয়েছে, যেখানে দলের পয়েন্ট, দলের সহায়তা এবং দলের রিবাউন্ড হিসাবে ডেটা কলামগুলি যোগ করা হয়েছে। সমস্ত দিকনির্দেশগুলি ডেটাফ্রেমে বিভিন্ন মান দিয়ে বরাদ্দ করা হয়। এই অক্ষ প্যারামিটারটি এমন একটি গেম চেঞ্জার কারণ, সময়ের মধ্যে, আমাদের সেই ডেটাতে কাজ করতে হবে যেখানে আমরা এটি একটি কলাম প্লাস পয়েন্টে থাকতে চাই যা সম্পাদিত স্ট্যান্ডার্ড বিচ্যুতির গণনা করা হয়।
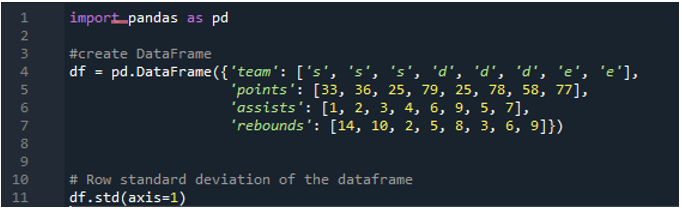
নিম্নলিখিত আউটপুট ডেটাফ্রেমের একটি সারিতে গণনা করা মানক বিচ্যুতি প্রদর্শন করে:
উপসংহার
পান্ডাস স্ট্যান্ডার্ড ডেভিয়েশন একটি খুব প্রযুক্তিগত ফাংশন, যা একটি খুব উপকারী ফাংশন কারণ এটি পান্ডাস ডেটাফ্রেমের উত্সাহ চুক্তির আদর্শ বিচ্যুতি খুঁজে পায়। এই সম্পাদকীয়তে, আমরা পান্ডাগুলিতে মানক বিচ্যুতি গণনা করার পদ্ধতিগুলি অধ্যয়ন করেছি। আমরা স্ট্যান্ডার্ড ডেভিয়েশন এবং একাধিক কলামের একক-কলাম গণনা করেছি এবং পুরো ডেটাফ্রেমের স্ট্যান্ডার্ড ডেভিয়েশন একসাথে গণনা করেছি। যতক্ষণ না সেগুলি ধারাবাহিকভাবে এবং পছন্দসই ফলাফলের সাথে ব্যবহার করা হয় ততক্ষণ পর্যন্ত সমস্ত কৌশলগুলি ভালভাবে কাজ করে।