এই পোস্টটি PostgreSQL পার্টিশন কভার করে। আমরা বিভিন্ন বিভাজন বিকল্পগুলি নিয়ে আলোচনা করব যা আপনি ব্যবহার করতে পারেন এবং আরও ভালভাবে বোঝার জন্য কীভাবে সেগুলি ব্যবহার করবেন তার উদাহরণ দেব।
কিভাবে PostgreSQL পার্টিশন তৈরি করবেন
যেকোনো ডাটাবেসে একাধিক এন্ট্রি সহ অসংখ্য টেবিল থাকতে পারে। সহজ ব্যবস্থাপনার জন্য, আপনার টেবিলগুলিকে বিভাজন করা উচিত যা ডাটাবেস অপ্টিমাইজেশানের জন্য এবং নির্ভরযোগ্যতার জন্য একটি দুর্দান্ত এবং প্রস্তাবিত ডেটা গুদাম রুটিন। আপনি তালিকা, পরিসীমা এবং হ্যাশ সহ বিভিন্ন পার্টিশন তৈরি করতে পারেন। প্রতিটি বিস্তারিত আলোচনা করা যাক।
1. তালিকা বিভাজন
কোনো পার্টিশন বিবেচনা করার আগে, আমাদের অবশ্যই একটি টেবিল তৈরি করতে হবে যা আমরা পার্টিশনের জন্য ব্যবহার করব। টেবিল তৈরি করার সময়, সমস্ত পার্টিশনের জন্য প্রদত্ত সিনট্যাক্স অনুসরণ করুন:
টেবিল তৈরি করুন টেবিল_নাম(কলাম 1 ডেটা_টাইপ, কলাম 2 ডেটা_টাইপ)
'টেবিল_নাম' হল আপনার টেবিলের বিভিন্ন কলামের পাশাপাশি টেবিলের নাম এবং তাদের ডেটা প্রকার। 'পার্টিশন_কি' এর জন্য, এটি সেই কলাম যার দ্বারা পার্টিশন করা হবে। উদাহরণস্বরূপ, নিম্নলিখিত চিত্রটি দেখায় যে আমরা তিনটি কলাম সহ 'কোর্স' টেবিল তৈরি করেছি। তাছাড়া, আমাদের পার্টিশনের ধরন হল LIST, এবং আমরা আমাদের পার্টিশন কী হিসাবে ফ্যাকাল্টি কলাম নির্বাচন করি:

একবার টেবিল তৈরি হয়ে গেলে, আমাদের প্রয়োজনীয় বিভিন্ন পার্টিশন তৈরি করতে হবে। এর জন্য, নিম্নলিখিত সিনট্যাক্সের সাথে এগিয়ে যান:
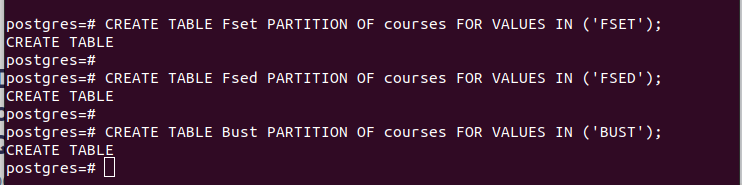
VALUES IN (VALUE);উদাহরণস্বরূপ, নিম্নলিখিত চিত্রের প্রথম উদাহরণটি দেখায় যে আমরা 'Fset' নামে একটি পার্টিশন টেবিল তৈরি করেছি যা 'ফ্যাকাল্টি' কলামের সমস্ত মান ধারণ করে যা আমরা আমাদের পার্টিশন কী হিসাবে নির্বাচন করেছি যার মান হল 'FSET'। আমরা আমাদের তৈরি করা অন্য দুটি পার্টিশনের জন্য একই যুক্তি ব্যবহার করেছি।
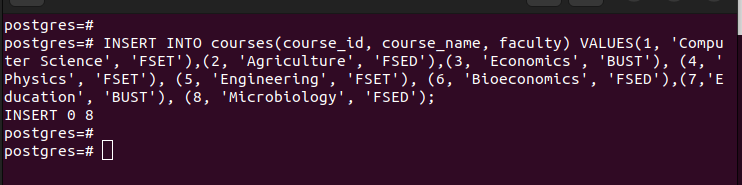
একবার আপনার পার্টিশন হয়ে গেলে, আপনি আমাদের তৈরি করা মূল টেবিলে মান সন্নিবেশ করতে পারেন। আপনার সন্নিবেশ করা প্রতিটি মান আপনার নির্বাচিত পার্টিশন কী-র মানগুলির উপর ভিত্তি করে সংশ্লিষ্ট পার্টিশনের সাথে মিলে যায়।
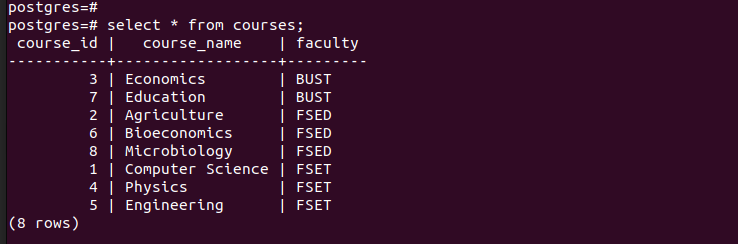
যদি আমরা মূল টেবিলের সমস্ত এন্ট্রি তালিকাভুক্ত করি, তাহলে আমরা দেখতে পাব যে এতে আমাদের সন্নিবেশ করা সমস্ত এন্ট্রি রয়েছে।
আমরা সফলভাবে পার্টিশন তৈরি করেছি কিনা তা যাচাই করতে, তৈরি করা প্রতিটি পার্টিশনের রেকর্ড পরীক্ষা করা যাক।
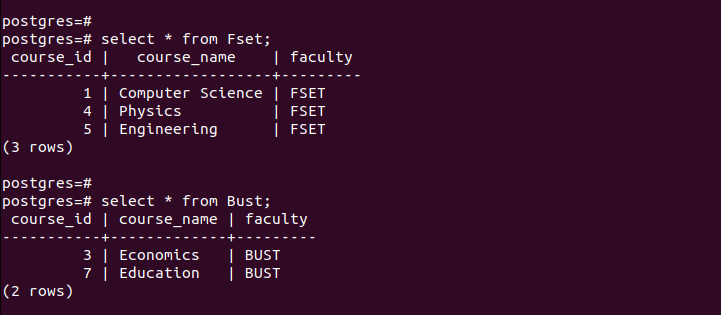
লক্ষ্য করুন কিভাবে প্রতিটি বিভাজিত টেবিল শুধুমাত্র এন্ট্রি ধারণ করে যা পার্টিশন করার সময় সংজ্ঞায়িত মানদণ্ডের সাথে মেলে। এইভাবে তালিকা দ্বারা বিভাজন কাজ করে।
2. রেঞ্জ পার্টিশনিং
পার্টিশন তৈরির আরেকটি মানদণ্ড হল RANGE বিকল্প ব্যবহার করা। এর জন্য, আমাদের অবশ্যই পরিসরের জন্য ব্যবহার করার জন্য শুরু এবং শেষ মানগুলি নির্দিষ্ট করতে হবে। তারিখের সাথে কাজ করার সময় এই পদ্ধতিটি ব্যবহার করা আদর্শ।
প্রধান টেবিল তৈরির জন্য এর সিনট্যাক্স নিম্নরূপ:
সারণী তৈরি করুন টেবিল_নাম(কলাম 1 ডেটা_টাইপ, কলাম 2 ডেটা_টাইপ) রেঞ্জ অনুসারে পার্টিশন (পার্টিশন_কী);আমরা 'কাস্ট_অর্ডার' টেবিল তৈরি করেছি এবং তারিখটিকে আমাদের 'পার্টিশন_কি' হিসাবে ব্যবহার করার জন্য নির্দিষ্ট করেছি।

পার্টিশন তৈরি করতে, নিম্নলিখিত সিনট্যাক্স ব্যবহার করুন:
(start_value) থেকে (end_value);আমরা 'তারিখ' কলাম ব্যবহার করে আমাদের পার্টিশনগুলিকে ত্রৈমাসিকভাবে কাজ করার জন্য সংজ্ঞায়িত করেছি।
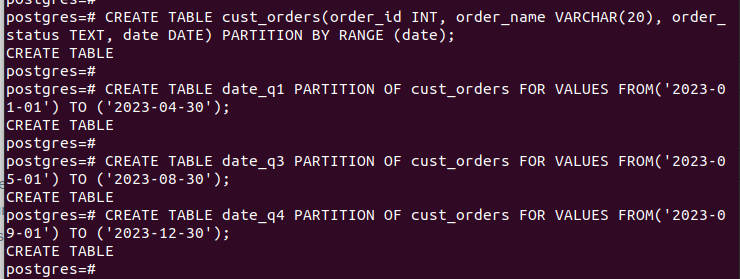
সমস্ত পার্টিশন তৈরি এবং ডেটা সন্নিবেশ করার পরে, আমাদের টেবিলটি এইরকম দেখায়:
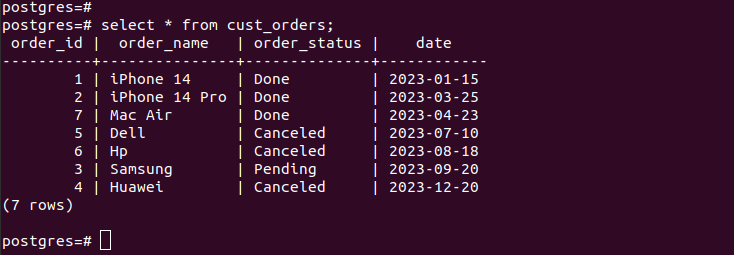
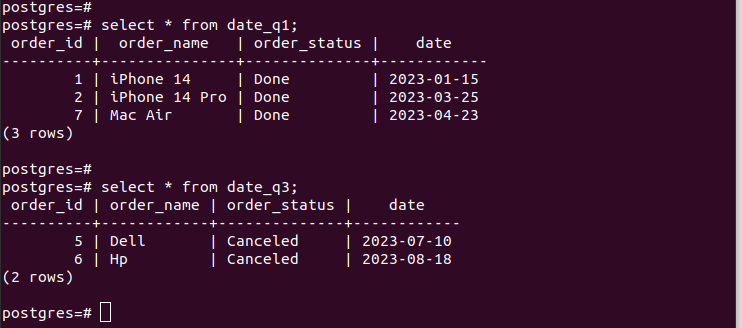
যদি আমরা তৈরি করা পার্টিশনের এন্ট্রিগুলি পরীক্ষা করি, আমরা যাচাই করি যে আমাদের পার্টিশন কাজ করে এবং আমাদের নির্দিষ্ট করা পার্টিশনের মানদণ্ড অনুযায়ী আমাদের কাছে উপযুক্ত রেকর্ড রয়েছে। আপনি আপনার টেবিলে যে সমস্ত নতুন এন্ট্রি যোগ করেন, সেগুলি স্বয়ংক্রিয়ভাবে সংশ্লিষ্ট পার্টিশনে যুক্ত হয়ে যায়।
3. হ্যাশ পার্টিশনিং
শেষ বিভাজন মাপদণ্ড যা আমরা আলোচনা করব তা হল হ্যাশ ব্যবহার করা। আসুন দ্রুত নিম্নলিখিত সিনট্যাক্স ব্যবহার করে প্রধান টেবিল তৈরি করি:
টেবিল তৈরি করুন টেবিল_নাম(কলাম 1 ডেটা_টাইপ, কলাম 2 ডেটা_টাইপ) হ্যাশ দ্বারা পার্টিশন (পার্টিশন_কী); 
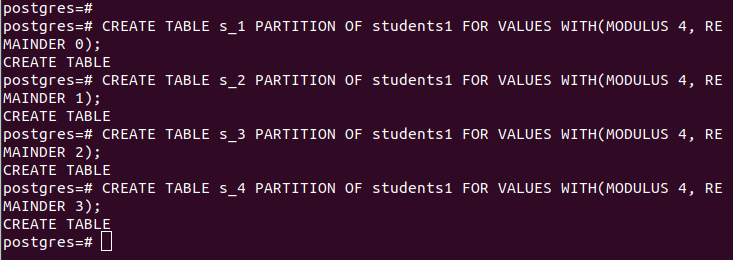
হ্যাশ দিয়ে পার্টিশন করার সময়, আপনাকে অবশ্যই মডুলাস এবং অবশিষ্টাংশ সরবরাহ করতে হবে, আপনার নির্দিষ্ট 'পার্টিশন_কি' এর হ্যাশ মান দ্বারা বিভক্ত করা সারিগুলি। আমাদের ক্ষেত্রে, আমরা 4 এর একটি মডুলাস ব্যবহার করি।
আমাদের সিনট্যাক্স নিম্নরূপ:
মানগুলির জন্য মূল_সারণীর টেবিল পার্টিশন_টেবিল পার্টিশন তৈরি করুন (মডুলাস সংখ্যা 1, অবশিষ্ট সংখ্যা 2);আমাদের পার্টিশনগুলি নিম্নরূপ:
'main_table' এর জন্য, এটিতে নিম্নলিখিত এন্ট্রিগুলি রয়েছে যা দেখানো হয়েছে:
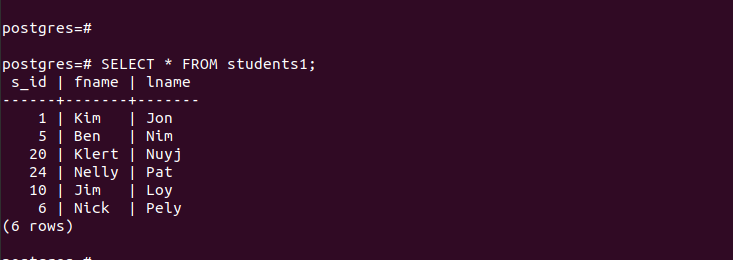
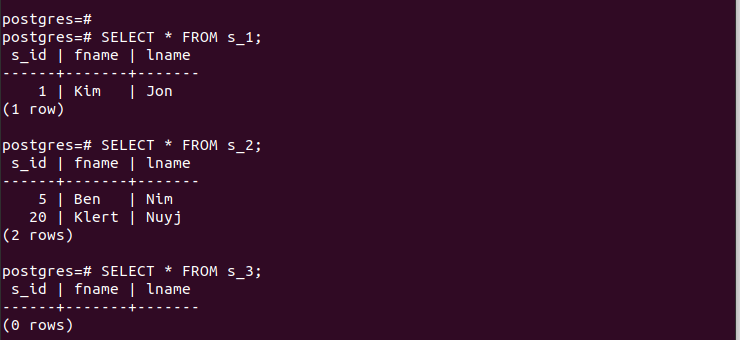
তৈরি করা পার্টিশনগুলির জন্য, আমরা তাদের এন্ট্রিগুলি দ্রুত অ্যাক্সেস করতে পারি এবং যাচাই করতে পারি যে আমাদের পার্টিশন কাজ করে।
উপসংহার
PostgreSQL পার্টিশনগুলি সময় বাঁচাতে এবং নির্ভরযোগ্যতা বাড়াতে ডাটাবেসকে অপ্টিমাইজ করার একটি সহজ উপায়। আমরা উপলব্ধ বিভিন্ন বিকল্প সহ বিশদভাবে বিভাজন নিয়ে আলোচনা করেছি। উপরন্তু, আমরা পার্টিশন কিভাবে বাস্তবায়ন করতে হয় তার উদাহরণ প্রদান করেছি। তাদের চেষ্টা করে দেখুন!