এই নিবন্ধে, আমরা বরাদ্দ কিভাবে আলোচনা করা হবে ভিন্ন এর মাধ্যমে স্মৃতি pytorch_cuda_alloc_conf 'পদ্ধতি।
PyTorch এ 'pytorch_cuda_alloc_conf' পদ্ধতি কি?
মৌলিকভাবে, ' pytorch_cuda_alloc_conf PyTorch কাঠামোর মধ্যে একটি পরিবেশ পরিবর্তনশীল। এই ভেরিয়েবলটি উপলব্ধ প্রসেসিং সংস্থানগুলির দক্ষ পরিচালনাকে সক্ষম করে যার অর্থ হল মডেলগুলি চালানো হয় এবং সর্বনিম্ন সম্ভাব্য সময়ের মধ্যে ফলাফল তৈরি করে। যদি সঠিকভাবে করা না হয়, ' ভিন্ন গণনা প্ল্যাটফর্ম প্রদর্শন করবে ' জ্ঞানের বাহিরে ” ত্রুটি এবং রানটাইমকে প্রভাবিত করে। যে মডেলগুলিকে প্রচুর পরিমাণে ডেটার উপর প্রশিক্ষিত করতে হবে বা বড় ' ব্যাচ মাপ ” রানটাইম ত্রুটি তৈরি করতে পারে কারণ ডিফল্ট সেটিংস তাদের জন্য যথেষ্ট নাও হতে পারে।
দ্য ' pytorch_cuda_alloc_conf 'ভেরিয়েবল নিম্নলিখিত ব্যবহার করে' বিকল্প সম্পদ বরাদ্দ পরিচালনা করতে:
- স্থানীয় : এই বিকল্পটি PyTorch-এ ইতিমধ্যে উপলব্ধ সেটিংস ব্যবহার করে প্রগতিশীল মডেলটিতে মেমরি বরাদ্দ করতে।
- max_split_size_mb : এটি নিশ্চিত করে যে নির্দিষ্ট আকারের চেয়ে বড় কোনো কোড ব্লক বিভক্ত না হয়। এটি প্রতিরোধ করার একটি শক্তিশালী হাতিয়ার ' বিভাজন ” আমরা এই নিবন্ধে প্রদর্শনের জন্য এই বিকল্পটি ব্যবহার করব।
- রাউন্ডআপ_পাওয়ার2_বিভাগ : এই বিকল্পটি বরাদ্দের আকারকে নিকটতম ' 2 এর শক্তি ” মেগাবাইটে বিভাজন (এমবি)।
- roundup_bypass_threshold_mb: এটি নির্দিষ্ট থ্রেশহোল্ডের চেয়ে বেশি তালিকাভুক্ত যেকোনো অনুরোধের জন্য বরাদ্দের আকারকে রাউন্ড আপ করতে পারে।
- আবর্জনা_সংগ্রহ_থ্রেশহোল্ড : এটি রিয়েল টাইমে GPU থেকে উপলব্ধ মেমরি ব্যবহার করে লেটেন্সি প্রতিরোধ করে যাতে পুনরুদ্ধার-সমস্ত প্রোটোকল শুরু না হয় তা নিশ্চিত করা যায়।
কিভাবে 'pytorch_cuda_alloc_conf' পদ্ধতি ব্যবহার করে মেমরি বরাদ্দ করবেন?
একটি বড় ডেটাসেট সহ যেকোন মডেলের জন্য অতিরিক্ত মেমরি বরাদ্দের প্রয়োজন যা ডিফল্টরূপে সেটের চেয়ে বেশি। মডেলের প্রয়োজনীয়তা এবং উপলব্ধ হার্ডওয়্যার সংস্থান বিবেচনায় রেখে কাস্টম বরাদ্দ নির্দিষ্ট করা প্রয়োজন।
ব্যবহার করতে নিচের ধাপগুলো অনুসরণ করুন ' pytorch_cuda_alloc_conf একটি জটিল মেশিন-লার্নিং মডেলে আরও মেমরি বরাদ্দ করার জন্য Google Colab IDE-তে পদ্ধতি:
ধাপ 1: Google Colab খুলুন
গুগলে সার্চ করুন সহযোগী ব্রাউজারে এবং একটি তৈরি করুন ' নতুন নোটবুক 'কাজ শুরু করতে:
ধাপ 2: একটি কাস্টম PyTorch মডেল সেট আপ করুন
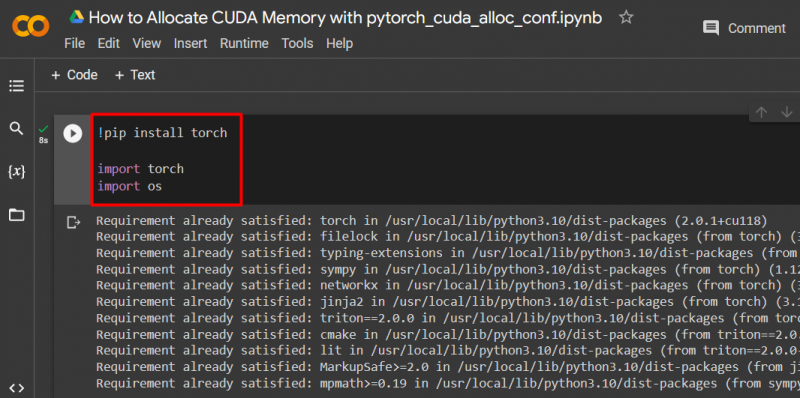
ব্যবহার করে একটি PyTorch মডেল সেট আপ করুন ' !পিপ ' ইনস্টলেশন প্যাকেজ ইনস্টল করার জন্য ' টর্চ 'লাইব্রেরি এবং ' আমদানি 'আমদানি করার আদেশ' টর্চ ' এবং ' আপনি প্রকল্পের মধ্যে লাইব্রেরি:
আমদানি মশাল
আমাদের আমদানি করুন
এই প্রকল্পের জন্য নিম্নলিখিত লাইব্রেরি প্রয়োজন:
- টর্চ - এটি মৌলিক গ্রন্থাগার যার উপর ভিত্তি করে PyTorch।
- আপনি - দ্য ' অপারেটিং সিস্টেম লাইব্রেরি পরিবেশের ভেরিয়েবলের সাথে সম্পর্কিত কাজগুলি পরিচালনা করতে ব্যবহৃত হয় যেমন ' pytorch_cuda_alloc_conf ' সেইসাথে সিস্টেম ডিরেক্টরি এবং ফাইল অনুমতি:
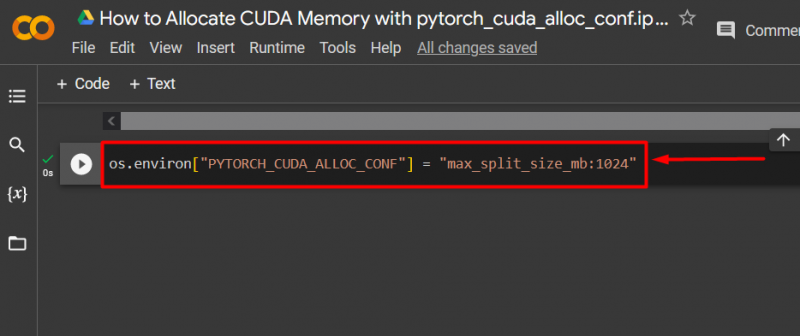
ধাপ 3: CUDA মেমরি বরাদ্দ করুন
ব্যবহার ' pytorch_cuda_alloc_conf ' ব্যবহার করে সর্বাধিক বিভক্ত আকার নির্দিষ্ট করার পদ্ধতি max_split_size_mb ”:
ধাপ 4: আপনার PyTorch প্রকল্পের সাথে চালিয়ে যান
নির্দিষ্ট করার পর ' ভিন্ন 'এর সাথে স্থান বরাদ্দ' max_split_size_mb ' বিকল্পে, ভয় ছাড়াই স্বাভাবিক হিসাবে পাইটর্চ প্রকল্পে কাজ চালিয়ে যান জ্ঞানের বাহিরে ' ত্রুটি.
বিঃদ্রঃ : আপনি এখানে আমাদের Google Colab নোটবুক অ্যাক্সেস করতে পারেন লিঙ্ক .
প্রো-টিপ
পূর্বে উল্লিখিত হিসাবে, ' pytorch_cuda_alloc_conf ” পদ্ধতিটি উপরের যেকোনও বিকল্প গ্রহণ করতে পারে। আপনার গভীর শিক্ষার প্রকল্পগুলির নির্দিষ্ট প্রয়োজনীয়তা অনুযায়ী সেগুলি ব্যবহার করুন।
সফলতার ! আমরা শুধু দেখিয়েছি কিভাবে ব্যবহার করতে হয় ' pytorch_cuda_alloc_conf একটি নির্দিষ্ট করার পদ্ধতি max_split_size_mb একটি PyTorch প্রকল্পের জন্য।
উপসংহার
ব্যবহার ' pytorch_cuda_alloc_conf ” মডেলের প্রয়োজনীয়তা অনুসারে এর উপলব্ধ বিকল্পগুলির যে কোনও একটি ব্যবহার করে CUDA মেমরি বরাদ্দ করার পদ্ধতি। এই বিকল্পগুলি প্রতিটি ভাল রানটাইম এবং মসৃণ ক্রিয়াকলাপগুলির জন্য PyTorch প্রকল্পগুলির মধ্যে একটি নির্দিষ্ট প্রক্রিয়াকরণ সমস্যা দূর করার জন্য বোঝানো হয়। এই নিবন্ধে, আমরা ব্যবহার করার জন্য সিনট্যাক্স প্রদর্শন করেছি ' max_split_size_mb ” বিভাজনের সর্বোচ্চ আকার নির্ধারণ করার বিকল্প।