পূর্বশর্ত
এই টিউটোরিয়ালের উদাহরণগুলি অনুশীলন করার আগে আপনাকে ক্লায়েন্টের সাথে ডাটাবেস সার্ভার ইনস্টল করতে হবে। মারিয়াডিবি ডাটাবেস সার্ভার এবং ক্লায়েন্ট এই টিউটোরিয়ালে ব্যবহার করা হয়েছে।
1. সিস্টেম আপডেট করতে নিম্নলিখিত কমান্ডগুলি চালান:
$ sudo apt- আপডেট পান
2. MariaDB সার্ভার এবং ক্লায়েন্ট ইনস্টল করতে নিম্নলিখিত কমান্ডটি চালান:
$ sudo apt-get install mariadb-server mariadb-client
3. MariaDB ডাটাবেসের জন্য নিরাপত্তা স্ক্রিপ্ট ইনস্টল করতে নিম্নলিখিত কমান্ডটি চালান:
$ sudo mysql_secure_installation
4. MariaDB সার্ভার পুনরায় চালু করতে নিম্নলিখিত কমান্ডটি চালান:
$ sudo /etc/init.d/mariadb পুনরায় চালু করুন
6. MariaDB সার্ভারে লগ ইন করতে নিম্নলিখিত কমান্ডটি চালান:
$ sudo mariadb -u root -pSQL কোয়েরি উদাহরণের তালিকা
- ডাটাবেস তৈরি করুন
- টেবিল তৈরি করুন
- টেবিলের নাম পরিবর্তন করুন
- টেবিলে একটি নতুন কলাম যোগ করুন
- টেবিল থেকে কলাম সরান
- টেবিলে একটি একক সারি ঢোকান
- টেবিলে একাধিক সারি সন্নিবেশ করান
- টেবিল থেকে বিশেষ ক্ষেত্র সব পড়ুন
- টেবিল থেকে ডেটা ফিল্টার করার পরে টেবিলটি পড়ুন
- বুলিয়ান লজিকের উপর ভিত্তি করে ডেটা ফিল্টার করার পরে টেবিলটি পড়ুন
- ডেটা পরিসরের উপর ভিত্তি করে সারিগুলি ফিল্টার করার পরে টেবিলটি পড়ুন
- বিশেষ কলামের উপর ভিত্তি করে টেবিল সাজানোর পর টেবিলটি পড়ুন।
- কলামের বিকল্প নাম সেট করে টেবিলটি পড়ুন
- সারণীতে মোট সারির সংখ্যা গণনা করুন
- একাধিক টেবিল থেকে ডেটা পড়ুন
- বিশেষ ক্ষেত্রগুলিকে গোষ্ঠীবদ্ধ করে টেবিলটি পড়ুন
- ডুপ্লিকেট মান বাদ দেওয়ার পরে টেবিলটি পড়ুন
- সারি সংখ্যা সীমাবদ্ধ করে টেবিলটি পড়ুন
- আংশিক মিলের উপর ভিত্তি করে টেবিলটি পড়ুন
- টেবিলের বিশেষ ক্ষেত্রের যোগফল গণনা করুন
- বিশেষ ক্ষেত্রের সর্বোচ্চ এবং সর্বনিম্ন মান খুঁজুন
- একটি ক্ষেত্রের বিশেষ অংশের ডেটা পড়ুন
- সংযুক্তির পরে টেবিলের ডেটা পড়ুন
- গাণিতিক গণনার পরে টেবিলের ডেটা পড়ুন
- টেবিলের একটি দৃশ্য তৈরি করুন
- বিশেষ অবস্থার উপর ভিত্তি করে টেবিল আপডেট করুন
- বিশেষ অবস্থার উপর ভিত্তি করে টেবিল ডেটা মুছুন
- টেবিল থেকে সমস্ত রেকর্ড মুছুন
- টেবিল ড্রপ
- ডাটাবেস ফেলে দিন
ডাটাবেস তৈরি করুন
ধরুন আমাদের লাইব্রেরি ম্যানেজমেন্ট সিস্টেমের জন্য একটি সাধারণ ডাটাবেস ডিজাইন করতে হবে। এই কাজটি করার জন্য, সার্ভারে একটি ডাটাবেস তৈরি করতে হবে যা একাধিক রিলেশনাল টেবিলকে কন্টেন্ট করে। ডাটাবেস সার্ভারে লগ ইন করার পরে, MariaDB ডাটাবেস সার্ভারে 'লাইব্রেরি' নামে একটি ডাটাবেস তৈরি করতে নিম্নলিখিত কমান্ডটি চালান:
সৃষ্টি তথ্যশালা গ্রন্থাগার;আউটপুট দেখায় যে লাইব্রেরি ডাটাবেস সার্ভারে তৈরি করা হয়েছে:
 বিভিন্ন ধরনের ডাটাবেস অপারেশন করতে সার্ভার থেকে ডাটাবেস নির্বাচন করতে নিম্নলিখিত কমান্ডটি চালান:
বিভিন্ন ধরনের ডাটাবেস অপারেশন করতে সার্ভার থেকে ডাটাবেস নির্বাচন করতে নিম্নলিখিত কমান্ডটি চালান:
আউটপুট দেখায় যে লাইব্রেরি ডাটাবেস নির্বাচন করা হয়েছে:

টেবিল তৈরি করুন
পরবর্তী ধাপে ডাটা সংরক্ষণের জন্য ডাটাবেসের জন্য প্রয়োজনীয় টেবিল তৈরি করা। টিউটোরিয়ালের এই অংশে তিনটি টেবিল তৈরি করা হয়েছে। এই বই, সদস্য, এবং borrow_info টেবিল.
- বইয়ের টেবিলটি বই সম্পর্কিত সমস্ত তথ্য সংরক্ষণ করে।
- সদস্যদের টেবিলে লাইব্রেরি থেকে বই ধার করা সদস্যদের সম্পর্কে সমস্ত তথ্য সংরক্ষণ করা হয়।
- borrow_info টেবিলটি কোন সদস্যের দ্বারা কোন বই ধার করা হয়েছে সে সম্পর্কে তথ্য সংরক্ষণ করে।
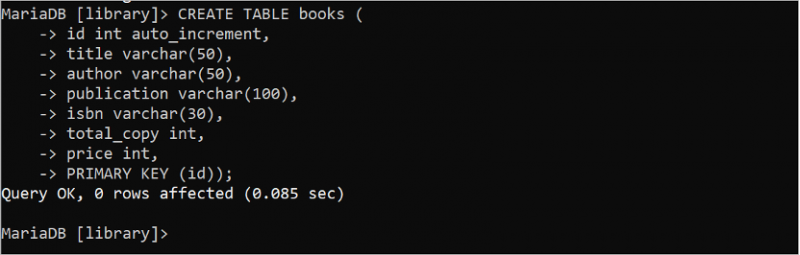
1. বই টেবিল
'লাইব্রেরি' ডাটাবেসে 'বই' নামের একটি টেবিল তৈরি করতে নিম্নলিখিত এসকিউএল স্টেটমেন্টটি চালান যাতে সাতটি ক্ষেত্র এবং একটি প্রাথমিক কী রয়েছে। এখানে, 'id' ক্ষেত্র হল প্রাথমিক কী এবং ডেটা টাইপ হল int। অটো_ইনক্রিমেন্ট বৈশিষ্ট্যটি 'আইডি' ক্ষেত্রের জন্য ব্যবহৃত হয়। সুতরাং, একটি নতুন সারি ঢোকানো হলে এই ক্ষেত্রের মান স্বয়ংক্রিয়ভাবে বৃদ্ধি পায়। varchar ডেটা টাইপ ভেরিয়েবল দৈর্ঘ্যের স্ট্রিং ডেটা সংরক্ষণ করতে ব্যবহৃত হয়। শিরোনাম, লেখক, প্রকাশনা, এবং isbn ক্ষেত্রগুলি স্ট্রিং ডেটা সংরক্ষণ করে। টোটাল_কপি এবং প্রাইস ফিল্ডের ডাটা টাইপ হল int। সুতরাং, এই ক্ষেত্রগুলি সংখ্যাসূচক তথ্য সংরক্ষণ করে।
সৃষ্টি টেবিল বই (আইডি আইএনটি অটো ,
শিরোনাম ভার্চার ( পঞ্চাশ ) ,
লেখক ভার্চার ( পঞ্চাশ ) ,
প্রকাশনা ভার্চার ( 100 ) ,
isbn ভার্চার ( 30 ) ,
মোট_কপি আইএনটি ,
মূল্য আইএনটি ,
প্রাথমিক চাবি ( আইডি ) ) ;
আউটপুট দেখায় যে 'বই' টেবিলটি সফলভাবে তৈরি হয়েছে:
2. সদস্য টেবিল
5টি ক্ষেত্র এবং একটি প্রাথমিক কী ধারণ করে 'লাইব্রেরি' ডাটাবেসে 'সদস্য' নামের একটি টেবিল তৈরি করতে নিম্নলিখিত SQL স্টেটমেন্টটি চালান। 'আইডি' ক্ষেত্রটিতে 'বই' টেবিলের মতো স্বয়ংক্রিয়_বৃদ্ধি বৈশিষ্ট্য রয়েছে। অন্যান্য ক্ষেত্রের ডেটা টাইপ হল varchar. সুতরাং, এই ক্ষেত্রগুলি স্ট্রিং ডেটা সংরক্ষণ করে।
সৃষ্টি টেবিল সদস্যদের (আইডি আইএনটি অটো ,
নাম ভার্চার ( পঞ্চাশ ) ,
ঠিকানা ভার্চার ( 200 ) ,
যোগাযোগের নম্বর ভার্চার ( পনের ) ,
ইমেইল ভার্চার ( পঞ্চাশ ) ,
প্রাথমিক চাবি ( আইডি ) ) ;
আউটপুট দেখায় যে 'সদস্য' টেবিলটি সফলভাবে তৈরি হয়েছে:

3. ধার_তথ্য টেবিল
6টি ক্ষেত্র রয়েছে এমন 'লাইব্রেরি' ডাটাবেসে 'borrow_info' নামের একটি টেবিল তৈরি করতে নিম্নলিখিত SQL স্টেটমেন্টটি চালান। এখানে, 'id' ক্ষেত্রটি প্রাথমিক কী তবে এই ক্ষেত্রের জন্য auto_increment বৈশিষ্ট্যটি ব্যবহার করা হয় না। সুতরাং, যখন টেবিলে একটি নতুন রেকর্ড ঢোকানো হয় তখন এই ক্ষেত্রের মধ্যে একটি অনন্য মান ম্যানুয়ালি ঢোকানো হয়। বুক_আইডি এবং সদস্য_আইডি ক্ষেত্রগুলি এই টেবিলের জন্য বিদেশী কী; এগুলি হল 'বই' টেবিল এবং 'সদস্য' টেবিলের প্রাথমিক কী। borrow_date এবং return_date ফিল্ডের ডেটা টাইপ হল তারিখ। সুতরাং, এই দুটি ক্ষেত্র 'YYYY-MM-DD' বিন্যাসে তারিখের মান সংরক্ষণ করে৷
সৃষ্টি টেবিল ধার_তথ্য (আইডি আইএনটি ,
ধার_তারিখ তারিখ ,
book_id আইএনটি ,
সদস্য আইডি আইএনটি ,
ফেরার_তারিখ তারিখ ,
স্ট্যাটাস ভার্চার ( 10 ) ,
প্রাথমিক চাবি ( আইডি ) ,
বিদেশী চাবি ( book_id ) তথ্যসূত্র বই ( আইডি ) ,
বিদেশী চাবি ( সদস্য আইডি ) তথ্যসূত্র সদস্যদের ( আইডি ) ) ;
আউটপুট দেখায় যে 'borrow_info' টেবিলটি সফলভাবে তৈরি হয়েছে:

টেবিলের নাম পরিবর্তন করুন
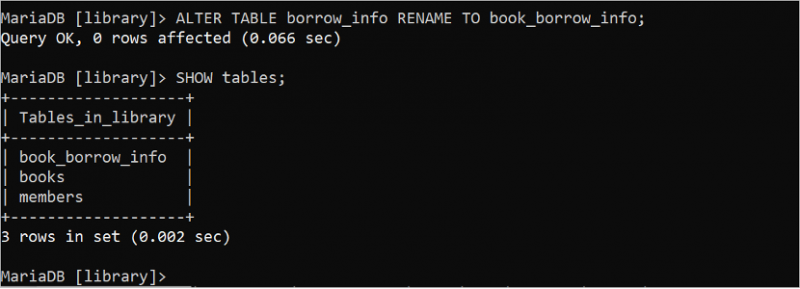
ALTER TABLE স্টেটমেন্ট SQL স্টেটমেন্টে একাধিক উদ্দেশ্যে ব্যবহার করা যেতে পারে। নিচের ALTER TABLE স্টেটমেন্টটি চালান “borrow_info” টেবিলের নাম পরিবর্তন করে “book_borrow_info”। এরপরে, টেবিলের নাম পরিবর্তন করা হয়েছে কি না তা পরীক্ষা করতে SHOW টেবিল স্টেটমেন্ট ব্যবহার করা যেতে পারে।
ALTER টেবিল ধার_তথ্য পুনরায় নাম দিন প্রতি বই_ধার_তথ্য;দেখান টেবিল ;
আউটপুট দেখায় যে টেবিলের নাম সফলভাবে পরিবর্তন করা হয়েছে এবং borrow_info টেবিলের নাম book_borrow_info এ পরিবর্তন করা হয়েছে:
টেবিলে একটি নতুন কলাম যোগ করুন
ALTER TABLE স্টেটমেন্টটি টেবিল তৈরি করার পরে এক বা একাধিক কলাম যোগ বা মুছে ফেলার জন্য ব্যবহার করা যেতে পারে। নিম্নলিখিত ALTER TABLE বিবৃতিটি টেবিলের সদস্যদের জন্য 'স্থিতি' নামে একটি নতুন ক্ষেত্র যোগ করে। DESCRIBE বিবৃতিটি টেবিলের কাঠামো পরিবর্তন করা হয়েছে কিনা তা দেখানোর জন্য ব্যবহৃত হয়।
ALTER টেবিল সদস্যদের যোগ করুন স্ট্যাটাস ভার্চার ( 10 ) ;বর্ণনা করুন সদস্য;
আউটপুট দেখায় যে 'স্ট্যাটাস' একটি নতুন কলাম 'সদস্য' টেবিলে যোগ করা হয়েছে এবং টেবিলের ডেটা টাইপ হল varchar:

টেবিল থেকে কলাম সরান
নিম্নলিখিত ALTER TABLE বিবৃতিটি 'সদস্য' টেবিল থেকে 'স্থিতি' নামক ক্ষেত্রটি মুছে দেয়। DESCRIBE বিবৃতিটি টেবিলের কাঠামো পরিবর্তন করা হয়েছে কিনা তা দেখানোর জন্য ব্যবহৃত হয়।
ALTER টেবিল সদস্যদের ড্রপ কলাম স্ট্যাটাস ;বর্ণনা করুন সদস্য;
আউটপুট দেখায় যে 'স্ট্যাটাস' কলামটি 'সদস্য' টেবিল থেকে সরানো হয়েছে:

টেবিলে একটি একক সারি ঢোকান
INSERT INTO স্টেটমেন্টটি টেবিলে এক বা একাধিক সারি সন্নিবেশ করতে ব্যবহৃত হয়। 'বই' টেবিলে একটি একক সারি সন্নিবেশ করতে নিম্নলিখিত SQL বিবৃতিটি চালান। এখানে, এই ক্যোয়ারী থেকে 'id' ক্ষেত্রটি বাদ দেওয়া হয়েছে কারণ এটি স্বয়ংক্রিয়ভাবে রেকর্ডে ঢোকানো হয় যখন স্বয়ংক্রিয়-বৃদ্ধি বৈশিষ্ট্যের জন্য একটি নতুন রেকর্ড ঢোকানো হয়। এই ক্ষেত্রটি INSERT বিবৃতিতে ব্যবহার করা হলে, মানটি অবশ্যই NULL হতে হবে।
ঢোকান INTO বই ( শিরোনাম , লেখক , প্রকাশনা , isbn , মোট_কপি , মূল্য )মূল্য ( '10 মিনিটে এসকিউএল' , 'বেন ফোর্টা' , 'স্যামস পাবলিশিং' , '784534235' , 5 , 39 ) ;
আউটপুট দেখায় যে একটি রেকর্ড সফলভাবে 'বই' টেবিলে যোগ করা হয়েছে:

ডেটা SET ক্লজ ব্যবহার করে টেবিলে ঢোকানো যেতে পারে যেখানে প্রতিটি ক্ষেত্রের মান আলাদাভাবে বরাদ্দ করা হয়। INSERT INTO এবং SET ক্লজগুলি ব্যবহার করে 'সদস্য' টেবিলে একটি একক সারি সন্নিবেশ করতে নিম্নলিখিত SQL স্টেটমেন্টটি চালান। 'আইডি' ক্ষেত্রটিও একই কারণে আগের উদাহরণের মতো এই প্রশ্নে বাদ দেওয়া হয়েছে।
ঢোকান INTO সদস্যদেরসেট নাম = 'জন সিনা' , ঠিকানা = '34, Dhanmondi 9/A, Dhaka' , যোগাযোগের নম্বর = '+14844731336' , ইমেইল = 'john@gmail.com' ;
আউটপুট দেখায় যে সদস্যদের টেবিলে একটি রেকর্ড সফলভাবে যোগ করা হয়েছে:

'book_borrow_info' টেবিলে একটি একক সারি সন্নিবেশ করতে নিম্নলিখিত SQL স্টেটমেন্টটি চালান:
ঢোকান INTO বই_ধার_তথ্য ( আইডি , ধার_তারিখ , book_id , সদস্য আইডি , ফেরার_তারিখ , স্ট্যাটাস )মূল্য ( 1 , '2023-03-12' , 1 , 1 , '2023-03-19' , 'ধার করা' ) ;
আউটপুট দেখায় যে 'book_borrow_info' টেবিলে একটি রেকর্ড যোগ করা হয়েছে:

টেবিলে একাধিক সারি সন্নিবেশ করান
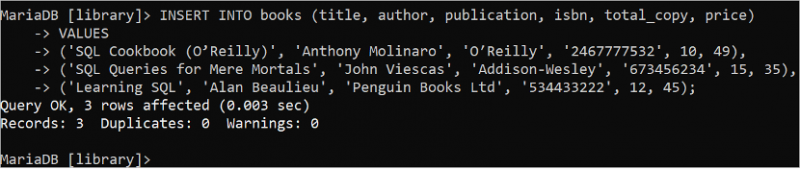
কখনও কখনও, এটি একটি একক INSERT INTO বিবৃতি ব্যবহার করে এক সময়ে অনেক রেকর্ড যোগ করতে হবে। একটি একক INSERT INTO স্টেটমেন্ট ব্যবহার করে 'বই' টেবিলে তিনটি রেকর্ড সন্নিবেশ করতে নিম্নলিখিত SQL স্টেটমেন্টটি চালান। এই ক্ষেত্রে, VALUES ধারাটি এক সময়ের জন্য ব্যবহার করা হয় এবং প্রতিটি রেকর্ডের ডেটা কমা দ্বারা পৃথক করা হয়।
ঢোকান INTO বই ( শিরোনাম , লেখক , প্রকাশনা , isbn , মোট_কপি , মূল্য )মূল্য
( 'এসকিউএল কুকবুক (ও'রিলি)' , 'অ্যান্টনি মোলিনারো' , 'ও'রিলি' , '2467777532' , 10 , 49 ) ,
( 'SQL Querys for Mere Mortals' , 'জন ভিসকাস' , 'অ্যাডিসন-ওয়েসলি' , '673456234' , পনের , 35 ) ,
( 'এসকিউএল শেখা' , 'অ্যালান বিউলিউ' , 'পেঙ্গুইন বুকস লিমিটেড' , '534433222' , 12 , চার পাঁচ ) ;
আউটপুট দেখায় যে তিনটি রেকর্ড 'বই' টেবিলে যোগ করা হয়েছে:
টেবিল থেকে বিশেষ ক্ষেত্র সব পড়ুন
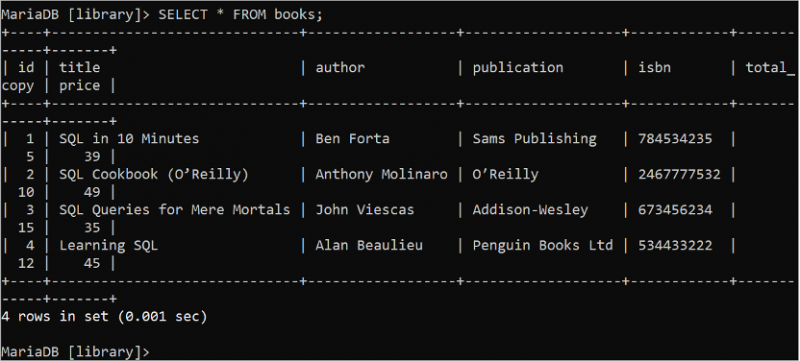
SELECT স্টেটমেন্টটি 'ডাটাবেস' টেবিল থেকে ডেটা পড়ার জন্য ব্যবহৃত হয়। SELECT স্টেটমেন্টে টেবিলের সমস্ত ক্ষেত্র বোঝাতে “*” চিহ্ন ব্যবহার করা হয়। বই টেবিলের সমস্ত রেকর্ড পড়তে নিম্নলিখিত SQL কমান্ডটি চালান:
নির্বাচন করুন * থেকে বইআউটপুট বই টেবিলের সমস্ত রেকর্ড দেখায় যাতে 4টি রেকর্ড রয়েছে:
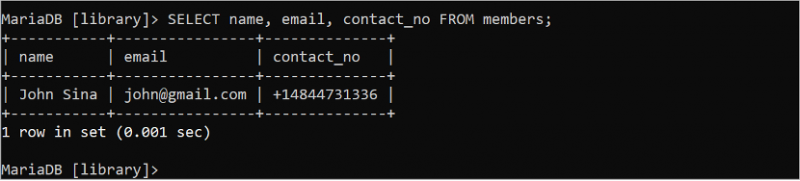
'সদস্য' টেবিলের তিনটি ক্ষেত্রের সমস্ত রেকর্ড পড়তে নিম্নলিখিত SQL কমান্ডটি চালান:
নির্বাচন করুন নাম , ইমেইল , যোগাযোগের নম্বর থেকে সদস্য;আউটপুট 'সদস্যদের' টেবিলের তিনটি ক্ষেত্রের সমস্ত রেকর্ড দেখায়:
টেবিল থেকে ডেটা ফিল্টার করার পরে টেবিলটি পড়ুন
WHERE ক্লজটি এক বা একাধিক শর্তের উপর ভিত্তি করে একটি টেবিল থেকে ডেটা পড়ার জন্য ব্যবহৃত হয়। 'বই' টেবিলের সমস্ত ক্ষেত্রের সমস্ত রেকর্ড পড়ার জন্য নিম্নলিখিত SELECT স্টেটমেন্টটি চালান যেখানে লেখকের নাম 'জন ভিসকাস'।
নির্বাচন করুন * থেকে বই কোথায় লেখক = 'জন ভিসকাস' ;'বই' টেবিলে একটি রেকর্ড রয়েছে যা আউটপুটে দেখানো WHERE ক্লজের অবস্থার সাথে মেলে:

বুলিয়ান লজিকের উপর ভিত্তি করে ডেটা ফিল্টার করার পরে টেবিলটি পড়ুন
বুলিয়ান AND লজিক WHERE ক্লজের একাধিক শর্ত সংজ্ঞায়িত করতে ব্যবহৃত হয় যা সত্য ফেরত দেয় যদি সমস্ত শর্ত সত্য হয়। 'বই' টেবিলের সমস্ত ফিল্ডের সমস্ত রেকর্ড পড়ার জন্য নিম্নলিখিত SELECT স্টেটমেন্টটি চালান যেখানে total_copy ক্ষেত্রের মান 10-এর বেশি এবং মূল্য ক্ষেত্রের মান 45-এর কম যৌক্তিক AND ব্যবহার করে৷
নির্বাচন করুন * থেকে বই কোথায় মোট_কপি > 10 এবং মূল্য < চার পাঁচ ;বইয়ের টেবিলে একটি রেকর্ড রয়েছে যা WHERE ক্লজের শর্তের সাথে মেলে যা আউটপুটে দেখানো হয়েছে:

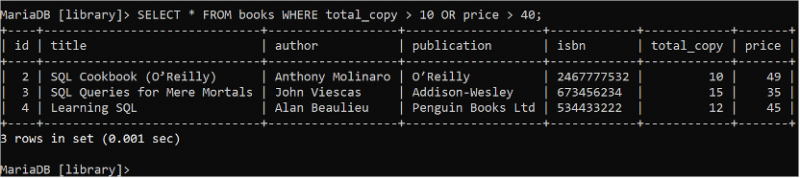
বুলিয়ান OR লজিকটি WHERE ক্লজের একাধিক শর্ত সংজ্ঞায়িত করতে ব্যবহৃত হয় যা সত্য ফেরত দেয় যদি কোনো শর্ত সত্য হয়। 'বই' টেবিলের সমস্ত ক্ষেত্রের সমস্ত রেকর্ড পড়ার জন্য নিম্নলিখিত SELECT স্টেটমেন্টটি চালান যেখানে total_copy ক্ষেত্রের মান 10 এর বেশি বা মূল্য ক্ষেত্রের মান 40 এর বেশি।
নির্বাচন করুন * থেকে বই কোথায় মোট_কপি > 10 বা মূল্য > 40 ;বই টেবিলে তিনটি রেকর্ড রয়েছে যা WHERE ক্লজের শর্তের সাথে মেলে যা আউটপুটে দেখানো হয়েছে:
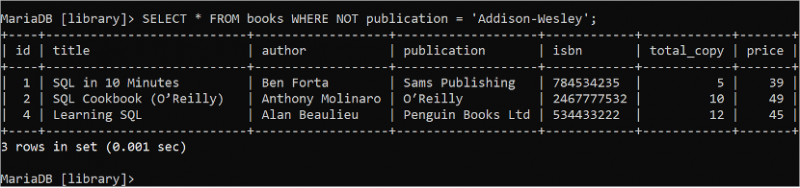
বুলিয়ান নট লজিক শর্তটি সত্য হলে মিথ্যা ফেরত দিতে ব্যবহৃত হয় এবং শর্তটি মিথ্যা হলে সত্য ফেরত দেয়। 'বই' টেবিলের সমস্ত ক্ষেত্রের সমস্ত রেকর্ড পড়ার জন্য নিম্নলিখিত SELECT স্টেটমেন্টটি চালান যেখানে লেখক ক্ষেত্রের মান 'Addison-Wesley' নয়।
নির্বাচন করুন * থেকে বই কোথায় না লেখক = 'অ্যাডিসন-ওয়েসলি' ;'বই' টেবিলে তিনটি রেকর্ড রয়েছে যা আউটপুটে দেখানো WHERE ক্লজের অবস্থার সাথে মেলে:
ডেটা পরিসরের উপর ভিত্তি করে সারিগুলি ফিল্টার করার পরে টেবিলটি পড়ুন
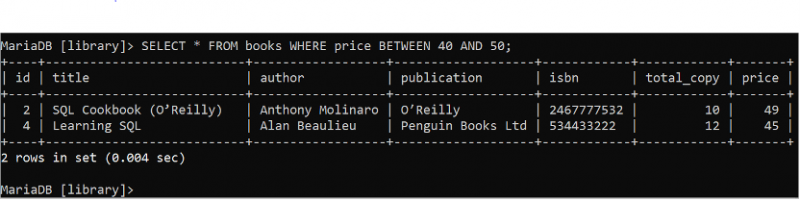
BETWEEN ক্লজটি ডাটাবেস টেবিল থেকে ডেটার পরিসর পড়তে ব্যবহৃত হয়। 'বই' টেবিলের সমস্ত ক্ষেত্রের সমস্ত রেকর্ড পড়ার জন্য নিম্নলিখিত SELECT স্টেটমেন্টটি চালান যেখানে মূল্য ক্ষেত্রের মান 40 থেকে 50 এর মধ্যে।
নির্বাচন করুন * থেকে বই কোথায় মূল্য মধ্যে 40 এবং পঞ্চাশ ;বইয়ের টেবিলে দুটি রেকর্ড রয়েছে যা WHERE ক্লজের শর্তের সাথে মেলে যা আউটপুটে দেখানো হয়েছে। মূল্য মানের বই, 39 এবং 35, ফলাফল সেট থেকে বাদ দেওয়া হয়েছে কারণ সেগুলি পরিসীমার বাইরে।
টেবিল সাজানোর পর টেবিলটি পড়ুন
ORDER BY ক্লজটি SELECT স্টেটমেন্টের ফলাফল সেটকে আরোহী বা অবরোহ ক্রমে সাজাতে ব্যবহৃত হয়। যদি ORDER BY ধারাটি ASC বা DESC ছাড়া ব্যবহার করা হয় তাহলে ফলাফল সেটটি ডিফল্টভাবে আরোহী ক্রমে সাজানো হয়। নিম্নলিখিত SELECT বিবৃতি শিরোনাম ক্ষেত্রের উপর ভিত্তি করে বই টেবিল থেকে সাজানো রেকর্ডগুলি পড়ে:
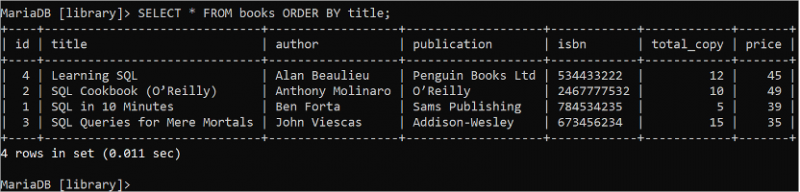
নির্বাচন করুন * থেকে বই অর্ডার করুন দ্বারা শিরোনাম;'বই' টেবিলের শিরোনাম ক্ষেত্রের ডেটা আউটপুটে আরোহী ক্রমে সাজানো হয়। 'Learning SQL' বইটি বর্ণানুক্রমিকভাবে প্রথমে আসে যদি 'বই' টেবিলের শিরোনাম ক্ষেত্রটি আরোহী ক্রমে সাজানো হয়।
কলামের বিকল্প নাম সেট করে টেবিলটি পড়ুন
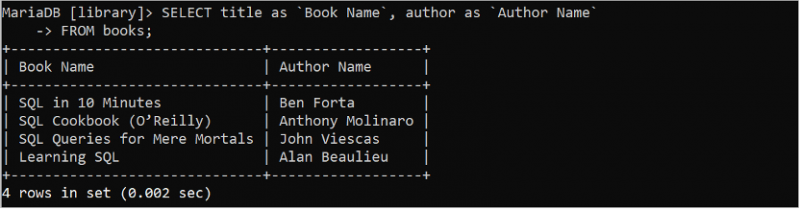
ফলাফল সেটটিকে আরও পাঠযোগ্য করতে কলামের বিকল্প নামটি ক্যোয়ারীতে ব্যবহার করা হয়। বিকল্প নাম 'AS' কীওয়ার্ড ব্যবহার করে সেট করা হয়েছে। নিম্নলিখিত SQL বিবৃতি বিকল্প নাম সেট করে শিরোনাম এবং লেখক ক্ষেত্রের মান প্রদান করে।
নির্বাচন করুন শিরোনাম এএস 'বইয়ের নাম' , লেখক এএস 'লেখকের নাম'থেকে বই
শিরোনাম ক্ষেত্রটি 'বইয়ের নাম' বিকল্পের সাথে প্রদর্শিত হয় এবং আউটপুটে 'লেখকের নাম' বিকল্প নামের সাথে লেখক ক্ষেত্রটি প্রদর্শিত হয়।
সারণীতে মোট সারির সংখ্যা গণনা করুন
COUNT() হল SQL এর একটি সমষ্টিগত ফাংশন যা নির্দিষ্ট ক্ষেত্র বা সমস্ত ক্ষেত্রের উপর ভিত্তি করে মোট সারির সংখ্যা গণনা করতে ব্যবহৃত হয়। '*' চিহ্নটি সমস্ত ক্ষেত্র বোঝাতে ব্যবহৃত হয় এবং COUNT(*) টেবিলের সমস্ত রেকর্ড গণনা করতে ব্যবহৃত হয়।
নিম্নলিখিত প্রশ্নটি বই টেবিলের মোট রেকর্ড গণনা করে:
নির্বাচন করুন COUNT ( * ) এএস 'মোট বই' থেকে বই'বই' টেবিলের চারটি রেকর্ড আউটপুটে দেখানো হয়েছে:

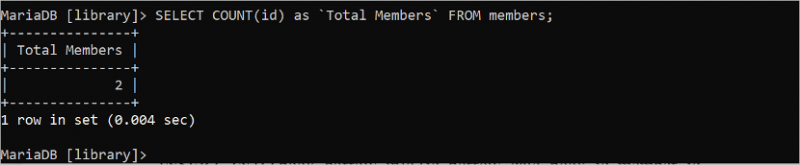
নিম্নলিখিত ক্যোয়ারী 'আইডি' ক্ষেত্রের উপর ভিত্তি করে 'সদস্য' টেবিলের মোট সারি গণনা করে:
নির্বাচন করুন COUNT ( আইডি ) এএস 'মোট সদস্য' থেকে সদস্য;'সদস্য' টেবিলে দুটি আইডি মান রয়েছে যা আউটপুটে মুদ্রিত হয়:
একাধিক টেবিল থেকে ডেটা পড়ুন
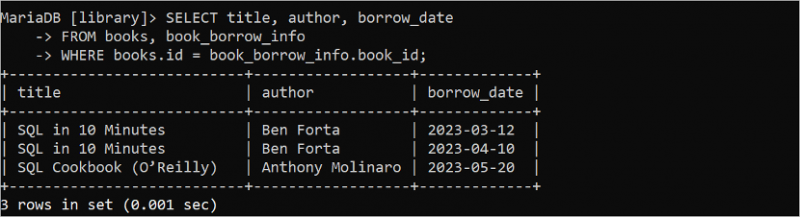
পূর্ববর্তী SELECT বিবৃতিগুলি একটি একক টেবিল থেকে ডেটা পুনরুদ্ধার করেছে। কিন্তু SELECT স্টেটমেন্টটি দুই বা ততোধিক টেবিল থেকে ডেটা পুনরুদ্ধার করতে ব্যবহার করা যেতে পারে। নিম্নলিখিত SELECT প্রশ্নটি 'বই' টেবিল থেকে শিরোনাম এবং লেখক ক্ষেত্রের মান এবং 'book_borrow_info' টেবিল থেকে borrow_date পড়ে।
নির্বাচন করুন শিরোনাম , লেখক , ধার_তারিখথেকে বই , বই_ধার_তথ্য
কোথায় বই . আইডি = বই_ধার_তথ্য . book_id;
নিম্নলিখিত আউটপুট দেখায় যে '10 মিনিটে এসকিউএল' বইটি দুইবার ধার করা হয়েছে এবং 'এসকিউএল কুকবুক (ও'রিলি)' বইটি একবার ধার করা হয়েছে:
এই টিউটোরিয়ালে ব্যাখ্যা করা হয়নি এমন INNER JOIN, OUTER JOIN ইত্যাদির মতো বিভিন্ন ধরনের JOINS ব্যবহার করে একাধিক টেবিল থেকে ডেটা পুনরুদ্ধার করা যেতে পারে।
বিশেষ ক্ষেত্রগুলিকে গোষ্ঠীবদ্ধ করে টেবিলটি পড়ুন
এক বা একাধিক ক্ষেত্রের উপর ভিত্তি করে সারিগুলিকে গোষ্ঠীবদ্ধ করে টেবিল থেকে রেকর্ডগুলি পড়ার জন্য GROUP BY ক্লজ ব্যবহার করা হয়। এই ধরনের ক্যোয়ারীকে সারাংশ ক্যোয়ারী বলা হয়। GROUP BY ক্লজের ব্যবহার পরীক্ষা করতে আপনাকে টেবিলে একাধিক সারি সন্নিবেশ করতে হবে। 'সদস্যদের' টেবিলে একটি রেকর্ড এবং 'book_borrow_info' টেবিলে দুটি রেকর্ড সন্নিবেশ করতে নিম্নলিখিত INSERT বিবৃতিগুলি চালান৷
ঢোকান INTO সদস্যদেরসেট নাম = 'সে হাসান' , ঠিকানা = '১১/এ, জিগাতলা, ঢাকা' , যোগাযোগের নম্বর = '+8801734563423' , ইমেইল = 'she@gmail.com' ;
ঢোকান INTO বই_ধার_তথ্য ( আইডি , ধার_তারিখ , book_id , সদস্য আইডি , ফেরার_তারিখ , স্ট্যাটাস )
মূল্য ( 2 , '2023-04-10' , 1 , 1 , '2023-04-15' , 'ফেরত' ) ;
ঢোকান INTO বই_ধার_তথ্য ( আইডি , ধার_তারিখ , book_id , সদস্য আইডি , ফেরার_তারিখ , স্ট্যাটাস )
মূল্য ( 3 , '2023-05-20' , 2 , 1 , '2023-05-30' , 'ধার করা' ) ;
পূর্ববর্তী প্রশ্নগুলি সম্পাদন করে ডেটা সন্নিবেশ করার পরে, নিম্নলিখিত SELECT স্টেটমেন্টটি চালান যা GROUP BY ক্লজ ব্যবহার করে প্রতিটি সদস্যের উপর ভিত্তি করে ধার করা বই এবং সদস্যের নামের মোট সংখ্যা গণনা করে। এখানে, COUNT() ফাংশনটি সেই ক্ষেত্রে কাজ করে যা GROUP BY ক্লজ ব্যবহার করে রেকর্ডগুলি পুনরায় গোষ্ঠীভুক্ত করতে ব্যবহৃত হয়। এখানে গ্রুপ করার জন্য 'সদস্য' টেবিলের book_id ক্ষেত্র ব্যবহার করা হয়েছে।
নির্বাচন করুন COUNT ( book_id ) এএস 'মোট বই ধার করা' , নাম এএস 'সদস্যের নাম' থেকে বই , সদস্যদের , বই_ধার_তথ্য কোথায় বই . আইডি = বই_ধার_তথ্য . book_id এবং সদস্যদের . আইডি = বই_ধার_তথ্য . সদস্য আইডি গ্রুপ দ্বারা বই_ধার_তথ্য . সদস্য আইডি;বই, “সদস্য” এবং “বুক_বোরো_ইনফো” টেবিলের তথ্য অনুসারে, “জন সিনা” 2টি বই এবং “এলা হাসান” 1টি বই ধার করেছে।

ডুপ্লিকেট মান বাদ দেওয়ার পরে টেবিলটি পড়ুন
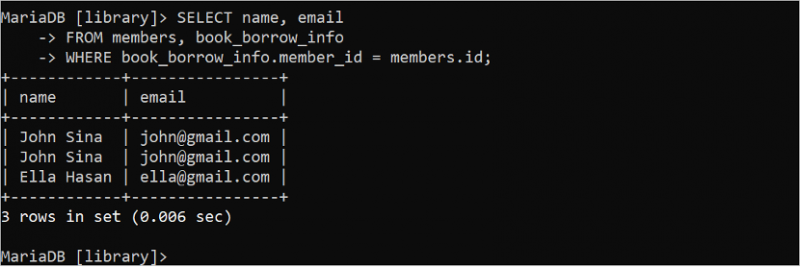
কখনও কখনও, অপ্রয়োজনীয় টেবিল ডেটার উপর ভিত্তি করে SELECT স্টেটমেন্টের ফলাফল সেটে ডুপ্লিকেট ডেটা তৈরি হয়। উদাহরণস্বরূপ, নিম্নলিখিত SELECT বিবৃতিটি 'book_borrow_info' টেবিলের ডেটার জন্য নকল রেকর্ড প্রদান করে।
নির্বাচন করুন নাম , ইমেইলথেকে সদস্যদের , বই_ধার_তথ্য
কোথায় বই_ধার_তথ্য . সদস্য আইডি = সদস্যদের . আইডি;
আউটপুটে, একই রেকর্ড দুবার দেখা যায় কারণ 'জন সিনা' সদস্য দুটি বই ধার করেছিলেন। এই সমস্যাটি DISTINCT কীওয়ার্ড ব্যবহার করে সমাধান করা যেতে পারে। এটি ক্যোয়ারী ফলাফল থেকে ডুপ্লিকেট রেকর্ডগুলি সরিয়ে দেয়।
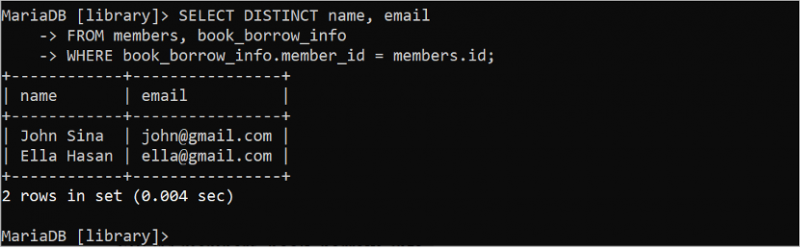
নিম্নলিখিত SELECT বিবৃতিটি 'সদস্য' এবং 'book_borrow_info' সারণী থেকে সেট করা ফলাফলের অনন্য রেকর্ড তৈরি করে কোয়েরিতে DISTINCT কীওয়ার্ড ব্যবহার করে ডুপ্লিকেট মানগুলি বাদ দেওয়ার পরে।
নির্বাচন করুন স্বতন্ত্র নাম , ইমেইলথেকে সদস্যদের , বই_ধার_তথ্য
কোথায় বই_ধার_তথ্য . সদস্য আইডি = সদস্যদের . আইডি;
আউটপুট দেখায় যে ডুপ্লিকেট মান ফলাফল সেট থেকে সরানো হয়েছে:
সারি সংখ্যা সীমাবদ্ধ করে টেবিলটি পড়ুন
কখনও কখনও, ফলাফল সেটের শুরু থেকে, ফলাফল সেটের শেষ থেকে বা সারি সংখ্যা সীমিত করে ডাটাবেস টেবিল থেকে ফলাফল সেটের মাঝখানে রেকর্ডের নির্দিষ্ট সংখ্যা পড়তে হয়। এটা অনেক উপায়ে করা যেতে পারে. সারিগুলি সীমাবদ্ধ করার আগে, বই টেবিলে কতগুলি রেকর্ড বিদ্যমান তা পরীক্ষা করতে নিম্নলিখিত SQL বিবৃতিটি চালান:
নির্বাচন করুন * থেকে বইআউটপুট দেখায় যে বই টেবিলের চারটি রেকর্ড রয়েছে:

নিম্নলিখিত SELECT স্টেটমেন্টটি 2 এর মান সহ LIMIT ক্লজ ব্যবহার করে 'বই' টেবিল থেকে প্রথম দুটি রেকর্ড পড়ে:
নির্বাচন করুন * থেকে বই সীমা 2 ;'বই' টেবিলের প্রথম দুটি রেকর্ড পুনরুদ্ধার করা হয়েছে যা আউটপুটে দেখানো হয়েছে:

FETCH ক্লজ হল LIMIT ক্লজের বিকল্প এবং এর ব্যবহার নিম্নলিখিত SELECT স্টেটমেন্টে দেখানো হয়েছে। 'বই' টেবিলের প্রথম 3টি রেকর্ড SELECT স্টেটমেন্টে FETCH FIRST 3 ROWS ONLY ক্লজ ব্যবহার করে পুনরুদ্ধার করা হয়েছে:
নির্বাচন করুন * থেকে বই আনুন প্রথম 3 সারি কেবল ;আউটপুট 'বই' টেবিলের প্রথম 3টি রেকর্ড দেখায়:

৩টি থেকে দুটি রেকর্ড rd বই টেবিলের সারি নিম্নলিখিত SELECT স্টেটমেন্ট কার্যকর করার মাধ্যমে পুনরুদ্ধার করা হয়। LIMIT ক্লজটি এখানে 2, 2 মানের সাথে ব্যবহার করা হয়েছে যেখানে প্রথম 2 টেবিলের সারির প্রারম্ভিক অবস্থান নির্ধারণ করে যা 0 থেকে গণনা শুরু হয় এবং দ্বিতীয় 2টি প্রারম্ভিক অবস্থান থেকে গণনা শুরু করে এমন সারির সংখ্যা নির্ধারণ করে।
নির্বাচন করুন * থেকে বই সীমা 2 , 2 ;পূর্ববর্তী ক্যোয়ারীটি চালানোর পরে নিম্নলিখিত আউটপুটটি উপস্থিত হয়:

স্বয়ংক্রিয়-বর্ধিত প্রাথমিক কী মানের উপর ভিত্তি করে এবং LIMIT ক্লজ ব্যবহার করে সারণির শেষ থেকে রেকর্ডগুলিকে পাঠ করা যেতে পারে। নিম্নলিখিত SELECT স্টেটমেন্টটি চালান যা 'বই' টেবিল থেকে শেষ 2টি রেকর্ড পড়ে। এখানে, ফলাফল সেটটি 'id' ক্ষেত্রের উপর ভিত্তি করে অবরোহ ক্রমে সাজানো হয়েছে।
নির্বাচন করুন * থেকে বই অর্ডার করুন দ্বারা আইডি DESC সীমা 2 ;বই টেবিলের শেষ দুটি রেকর্ড নিম্নলিখিত আউটপুটে দেখানো হয়েছে:

আংশিক মিলের উপর ভিত্তি করে টেবিলটি পড়ুন
আংশিক মিলের মাধ্যমে টেবিল থেকে রেকর্ড পুনরুদ্ধার করতে LIKE ক্লজটি '%' চিহ্নের সাথে ব্যবহার করা হয়। নিম্নলিখিত SELECT স্টেটমেন্টটি 'বই' টেবিল থেকে রেকর্ডগুলি অনুসন্ধান করে যেখানে লেখক ক্ষেত্রের মানের শুরুতে LIKE ক্লজ ব্যবহার করে 'John' রয়েছে। এখানে, সার্চ স্ট্রিং এর শেষে “%” চিহ্ন ব্যবহার করা হয়েছে।
নির্বাচন করুন * থেকে বই কোথায় লেখক লাইক 'জন%' ;'বই' টেবিলে শুধুমাত্র একটি রেকর্ড বিদ্যমান যেখানে লেখক ক্ষেত্রের মানের শুরুতে 'জন' স্ট্রিং রয়েছে।

নিম্নলিখিত SELECT বিবৃতিটি 'বই' টেবিল থেকে রেকর্ডগুলি অনুসন্ধান করে যেখানে প্রকাশনা ক্ষেত্রের মানের শেষে LIKE ক্লজ ব্যবহার করে 'Ltd' রয়েছে। এখানে, সার্চ স্ট্রিং এর শুরুতে “%” চিহ্ন ব্যবহার করা হয়েছে:
নির্বাচন করুন * থেকে বই কোথায় প্রকাশনা লাইক '% লিমিটেড' ;'বই' টেবিলে শুধুমাত্র একটি রেকর্ড বিদ্যমান যেখানে প্রকাশনা ক্ষেত্রের শেষে 'লিমিটেড' স্ট্রিং রয়েছে।

নিম্নলিখিত SELECT বিবৃতিটি 'বই' টেবিল থেকে রেকর্ডগুলি অনুসন্ধান করে যেখানে শিরোনাম ক্ষেত্রে LIKE ক্লজ ব্যবহার করে মানটির যে কোনও জায়গায় 'কোয়েরি' রয়েছে। এখানে, সার্চ স্ট্রিং এর উভয় পাশে “%” চিহ্ন ব্যবহার করা হয়েছে:
নির্বাচন করুন * থেকে বই কোথায় শিরোনাম লাইক '% প্রশ্ন%' ;'বই' টেবিলে শুধুমাত্র একটি রেকর্ড বিদ্যমান যা শিরোনাম ক্ষেত্রে 'কোয়েরি' স্ট্রিং ধারণ করে।

টেবিলের বিশেষ ক্ষেত্রের যোগফল গণনা করুন
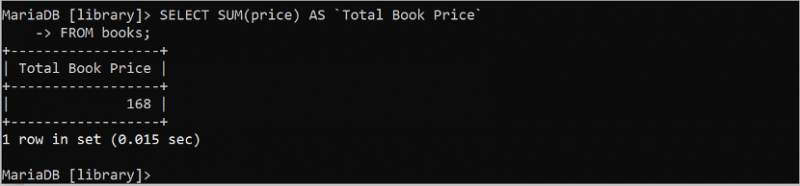
SUM() হল SQL-এর আরেকটি দরকারী সমষ্টিগত ফাংশন যা টেবিলের যেকোনো সাংখ্যিক ক্ষেত্রের মানের সমষ্টি গণনা করে। এই ফাংশনটি একটি আর্গুমেন্ট নেয় যা অবশ্যই সাংখ্যিক হতে হবে। নিম্নলিখিত SQL বিবৃতিটি 'বই' টেবিলের মূল্য ক্ষেত্রের সমস্ত মানের সমষ্টি গণনা করে যাতে পূর্ণসংখ্যার মান রয়েছে।
নির্বাচন করুন SUM ( মূল্য ) এএস 'মোট বইয়ের দাম'থেকে বই
আউটপুট 'বই' টেবিলের মূল্য ক্ষেত্রের সমস্ত মানের সমষ্টি মান দেখায়। মূল্য ক্ষেত্রের চারটি মান হল 39, 49, 35 এবং 45৷ এই মানের সমষ্টি হল 168৷
বিশেষ ক্ষেত্রের সর্বোচ্চ এবং সর্বনিম্ন মান খুঁজুন
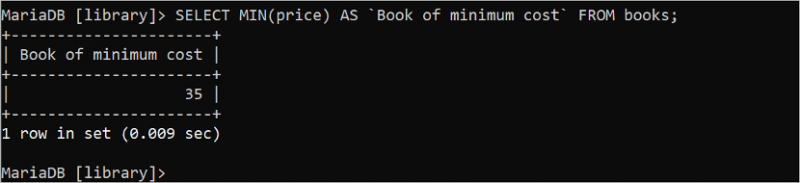
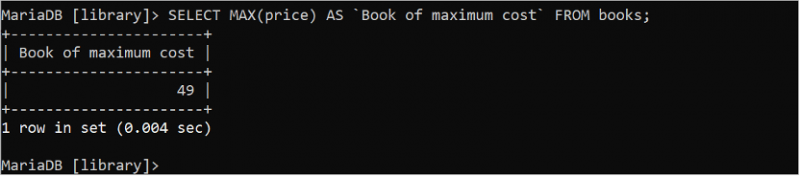
MIN() এবং MAX() সমষ্টিগত ফাংশনগুলি টেবিলের নির্দিষ্ট ক্ষেত্রের সর্বনিম্ন এবং সর্বাধিক মানগুলি খুঁজে বের করতে ব্যবহৃত হয়। উভয় ফাংশন একটি আর্গুমেন্ট নেয় যা অবশ্যই সাংখ্যিক হতে হবে। নিম্নলিখিত SQL স্টেটমেন্টটি 'বই' টেবিল থেকে ন্যূনতম মূল্যের মান খুঁজে বের করে যা একটি পূর্ণসংখ্যা।
নির্বাচন করুন MIN ( মূল্য ) এএস `ন্যূনতম মূল্যের বই` থেকে বইপঁয়ত্রিশ (35) হল মূল্য ক্ষেত্রের সর্বনিম্ন মান যা আউটপুটে মুদ্রিত হয়।
নিম্নলিখিত SQL বিবৃতি 'বই' টেবিল থেকে সর্বোচ্চ মূল্য মান খুঁজে বের করে:
নির্বাচন করুন MAX ( মূল্য ) এএস `সর্বোচ্চ মূল্যের বই` থেকে বইউনচল্লিশ (49) হল মূল্য ক্ষেত্রের সর্বোচ্চ মান যা আউটপুটে মুদ্রিত হয়।
ডেটা বা ফিল্ডের বিশেষ অংশ পড়ুন
SUBSTR() ফাংশনটি SQL স্টেটমেন্টে স্ট্রিং ডেটার নির্দিষ্ট অংশ বা টেবিলের নির্দিষ্ট ক্ষেত্রের মান পুনরুদ্ধার করতে ব্যবহৃত হয়। এই ফাংশনে তিনটি আর্গুমেন্ট রয়েছে। প্রথম আর্গুমেন্টে স্ট্রিং ভ্যালু বা টেবিলের ফিল্ড ভ্যালু থাকে যা একটি স্ট্রিং। দ্বিতীয় আর্গুমেন্টে সাব-স্ট্রিংটির প্রারম্ভিক অবস্থান রয়েছে যা প্রথম আর্গুমেন্ট থেকে পুনরুদ্ধার করা হয় এবং এই মানের গণনা 1 থেকে শুরু হয়। তৃতীয় আর্গুমেন্টে সাব-স্ট্রিংটির দৈর্ঘ্য রয়েছে যা প্রারম্ভিক অবস্থান থেকে গণনা শুরু করে।
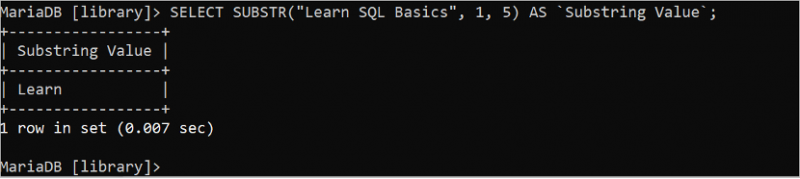
নিম্নলিখিত SELECT স্টেটমেন্টটি 'Learn SQL Basics' স্ট্রিং থেকে প্রথম পাঁচটি অক্ষর কেটে এবং প্রিন্ট করে যেখানে শুরুর অবস্থান 1 এবং দৈর্ঘ্য 5:
নির্বাচন করুন SUBSTR ( 'এসকিউএল বেসিক শিখুন' , 1 , 5 ) এএস `সাবস্ট্রিং মান` ;“Learn SQL Basics” স্ট্রিং এর প্রথম পাঁচটি অক্ষর হল “Learn” যা আউটপুটে প্রিন্ট করা হয়।
নিম্নোক্ত SELECT স্টেটমেন্টটি 'Learn SQL Basics' স্ট্রিং থেকে SQL কে কাট এবং প্রিন্ট করে যেখানে শুরুর অবস্থান 7 এবং দৈর্ঘ্য 3:
নির্বাচন করুন SUBSTR ( 'এসকিউএল বেসিক শিখুন' , 7 , 3 ) এএস `সাবস্ট্রিং মান` ;পূর্ববর্তী ক্যোয়ারীটি চালানোর পরে নিম্নলিখিত আউটপুটটি উপস্থিত হয়:

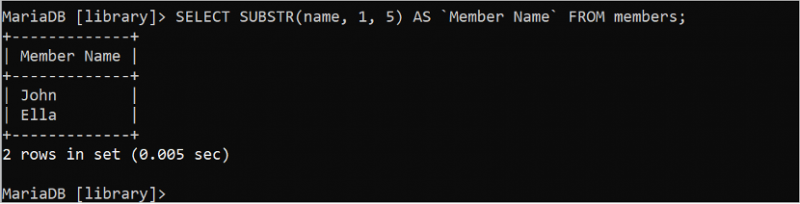
নিম্নলিখিত SELECT বিবৃতিটি 'সদস্যদের' টেবিলের নামের ক্ষেত্র থেকে প্রথম পাঁচটি অক্ষর কেটে এবং প্রিন্ট করে:
নির্বাচন করুন SUBSTR ( নাম , 1 , 5 ) এএস 'সদস্যের নাম' থেকে সদস্য;আউটপুট 'সদস্য' টেবিলের নামের ক্ষেত্রের প্রতিটি মানের প্রথম পাঁচটি অক্ষর দেখায়।
সংযুক্তির পরে টেবিলের ডেটা পড়ুন
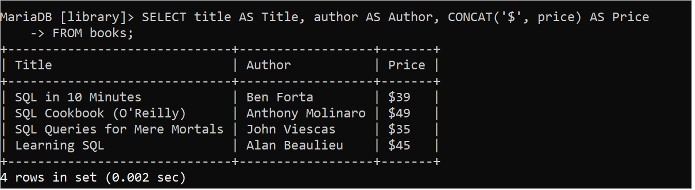
CONCAT() ফাংশনটি একটি টেবিলের এক বা একাধিক ক্ষেত্র একত্রিত করে বা স্ট্রিং ডেটা বা টেবিলের নির্দিষ্ট ক্ষেত্র মান যোগ করে আউটপুট তৈরি করতে ব্যবহৃত হয়। নিম্নলিখিত এসকিউএল স্টেটমেন্টটি 'বই' টেবিলের শিরোনাম, লেখক এবং মূল্য ক্ষেত্রের মানগুলি পড়ে এবং CONCAT() ফাংশন ব্যবহার করে মূল্য ক্ষেত্রের প্রতিটি মানের সাথে '$' স্ট্রিং মান যোগ করা হয়।
নির্বাচন করুন শিরোনাম এএস শিরোনাম , লেখক এএস লেখক , কনক্যাট ( '$' , মূল্য ) এএস দামথেকে বই
মূল্য ক্ষেত্রের মান '$' স্ট্রিং দিয়ে আউটপুটে মুদ্রিত হয়।
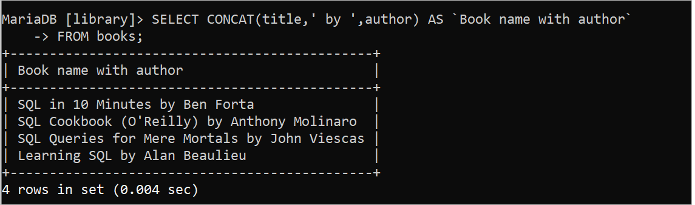
CONCAT() ফাংশন ব্যবহার করে 'by' স্ট্রিং মানের সাথে 'বই' টেবিলের শিরোনাম এবং লেখক ক্ষেত্রগুলির মানগুলিকে একত্রিত করতে নিম্নলিখিত SQL স্টেটমেন্টটি চালান:
নির্বাচন করুন কনক্যাট ( শিরোনাম , ' দ্বারা ' , লেখক ) এএস 'লেখকের সাথে বইয়ের নাম'থেকে বই
পূর্ববর্তী SELECT ক্যোয়ারীটি চালানোর পরে নিম্নলিখিত আউটপুটটি উপস্থিত হয়:
একটি গাণিতিক গণনার পরে টেবিল ডেটা পড়ুন
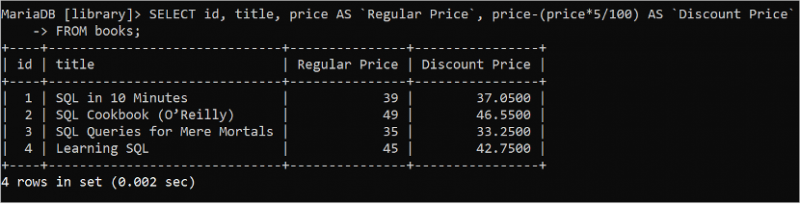
একটি SELECT স্টেটমেন্ট ব্যবহার করে টেবিলের মান পুনরুদ্ধার করার সময় যেকোনো গাণিতিক গণনা করা যেতে পারে। 5% ডিসকাউন্ট গণনা করার পরে আইডি, শিরোনাম, মূল্য এবং ছাড়কৃত মূল্য মান পড়তে নিম্নলিখিত SQL স্টেটমেন্টটি চালান।
নির্বাচন করুন আইডি , শিরোনাম , মূল্য এএস `নিয়মিত মূল্য` , মূল্য - ( মূল্য * 5 / 100 ) এএস `ছাড় মূল্য`থেকে বই
নিম্নলিখিত আউটপুট প্রতিটি বইয়ের নিয়মিত মূল্য এবং ডিসকাউন্ট মূল্য দেখায়:
টেবিলের একটি দৃশ্য তৈরি করুন
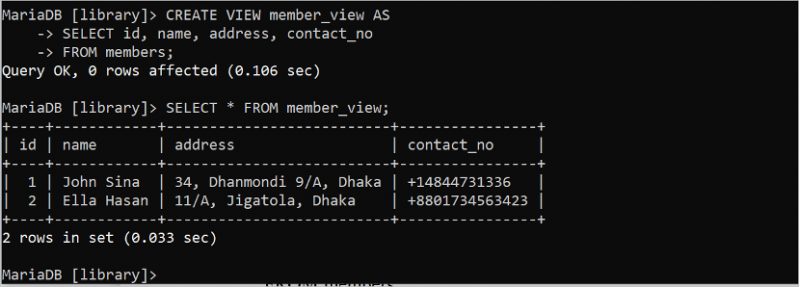
প্রশ্নটি সহজ করতে ভিআইডব্লিউ ব্যবহার করা হয় এবং ডাটাবেসে অতিরিক্ত নিরাপত্তা প্রদান করে। এটি একটি ভার্চুয়াল টেবিলের মতো কাজ করে যা এক বা একাধিক টেবিল থেকে তৈরি হয়। 'সদস্য' টেবিলের উপর ভিত্তি করে একটি সাধারণ ভিউ তৈরি এবং কার্যকর করার পদ্ধতি নিম্নলিখিত উদাহরণে দেখানো হয়েছে। SELECT স্টেটমেন্ট ব্যবহার করে VIEW সম্পাদিত হয়। নিম্নলিখিত SQL স্টেটমেন্টটি আইডি, নাম, ঠিকানা এবং contact_no ক্ষেত্র সহ 'সদস্যদের' টেবিলের একটি ভিউ তৈরি করে। SELECT স্টেটমেন্ট সদস্য_দর্শন চালায়।
সৃষ্টি দেখুন সদস্য_দর্শন এএসনির্বাচন করুন আইডি , নাম , ঠিকানা , যোগাযোগের নম্বর
থেকে সদস্য;
নির্বাচন করুন * থেকে সদস্য_দর্শন;
ভিউ তৈরি এবং কার্যকর করার পরে নিম্নলিখিত আউটপুটটি উপস্থিত হয়:
বিশেষ অবস্থার উপর ভিত্তি করে টেবিল আপডেট করুন
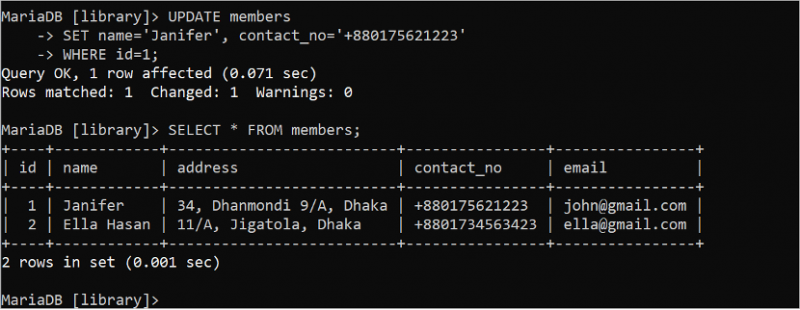
আপডেট বিবৃতিটি টেবিলের বিষয়বস্তু আপডেট করতে ব্যবহৃত হয়। যদি কোন আপডেট ক্যোয়ারী WHERE ক্লজ ছাড়া সম্পাদিত হয়, আপডেট ক্যোয়ারীতে ব্যবহৃত সমস্ত ক্ষেত্র আপডেট করা হয়। সুতরাং, সঠিক WHERE ক্লজ সহ একটি আপডেট স্টেটমেন্ট ব্যবহার করা প্রয়োজন। নাম এবং contact_no ফিল্ড আপডেট করতে নিম্নলিখিত UPDATE স্টেটমেন্টটি চালান যেখানে id ফিল্ডের মান 1 হয়। এরপর, ডেটা সঠিকভাবে আপডেট হয়েছে কিনা তা পরীক্ষা করতে SELECT স্টেটমেন্টটি চালান।
হালনাগাদ সদস্যদেরসেট নাম = 'জানিফার' , যোগাযোগের নম্বর = '+880175621223'
কোথায় আইডি = 1 ;
নির্বাচন করুন * থেকে সদস্য;
নিম্নলিখিত আউটপুট দেখায় যে আপডেট বিবৃতি সফলভাবে কার্যকর করা হয়েছে। নামের ক্ষেত্রের মান পরিবর্তন করে 'জেনিফার' করা হয়েছে এবং contact_no ফিল্ডটিকে রেকর্ডের '+880175621223' এ পরিবর্তিত করা হয়েছে যাতে আপডেট ক্যোয়ারী ব্যবহার করে 1 এর আইডি মান রয়েছে:
বিশেষ অবস্থার উপর ভিত্তি করে টেবিল ডেটা মুছুন
DELETE বিবৃতিটি নির্দিষ্ট বিষয়বস্তু বা টেবিলের সমস্ত বিষয়বস্তু মুছে ফেলার জন্য ব্যবহৃত হয়। WHERE ক্লজ ছাড়া কোনো DELETE ক্যোয়ারী কার্যকর করা হলে, সমস্ত ক্ষেত্র মুছে ফেলা হয়। সুতরাং, সঠিক WHERE ক্লজ সহ UPDATE স্টেটমেন্ট ব্যবহার করা প্রয়োজন। বই টেবিল থেকে সমস্ত ডেটা মুছে ফেলার জন্য নিম্নলিখিত DELETE স্টেটমেন্টটি চালান যেখানে id এর মান 4। এরপর, ডেটা সঠিকভাবে মুছে ফেলা হয়েছে কিনা তা পরীক্ষা করতে SELECT স্টেটমেন্টটি চালান।
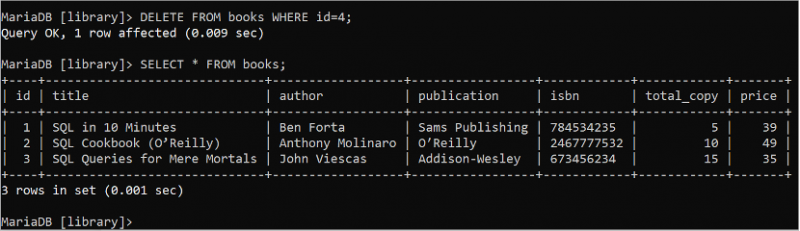
মুছে ফেলা থেকে বই কোথায় আইডি = 4 ;নির্বাচন করুন * থেকে বই
নিম্নলিখিত আউটপুট দেখায় যে DELETE বিবৃতি সফলভাবে কার্যকর করা হয়েছে। 4 ম DELETE ক্যোয়ারী ব্যবহার করে বই টেবিলের রেকর্ড মুছে ফেলা হয়:
টেবিল থেকে সমস্ত রেকর্ড মুছুন
যেখানে WHERE ক্লজটি বাদ দেওয়া হয়েছে সেখানে 'বই' টেবিল থেকে সমস্ত রেকর্ড মুছে ফেলার জন্য নিম্নলিখিত DELETE বিবৃতিটি চালান। এরপরে, টেবিলের বিষয়বস্তু পরীক্ষা করতে SELECT ক্যোয়ারীটি চালান।
মুছে ফেলা থেকে বই_ধার_তথ্য;নির্বাচন করুন * থেকে বই_ধার_তথ্য;
নিম্নলিখিত আউটপুট দেখায় যে 'বই' টেবিলটি ডিলিট কোয়েরি চালানোর পরে খালি রয়েছে:

যদি কোনো টেবিলে একটি স্বয়ংক্রিয়-বৃদ্ধি বৈশিষ্ট্য থাকে এবং সমস্ত রেকর্ড টেবিল থেকে মুছে ফেলা হয়, তাহলে টেবিলটি খালি করার পরে একটি নতুন রেকর্ড ঢোকানো হলে স্বয়ংক্রিয়-বৃদ্ধি ক্ষেত্রটি শেষ বৃদ্ধি থেকে গণনা শুরু করে। এই সমস্যাটি TRUNCATE স্টেটমেন্ট ব্যবহার করে সমাধান করা যেতে পারে। এটি টেবিল থেকে সমস্ত রেকর্ড মুছে ফেলার জন্যও ব্যবহৃত হয় কিন্তু স্বয়ংক্রিয়-বৃদ্ধি ক্ষেত্রটি টেবিল থেকে সমস্ত রেকর্ড মুছে ফেলার পরে 1 থেকে গণনা শুরু করে। TRUNCATE স্টেটমেন্টের SQL নিম্নলিখিতটিতে দেখানো হয়েছে:
ছিন্ন করুন বই_ধার_তথ্য;টেবিল ড্রপ
এক বা একাধিক টেবিল চেক করে বা টেবিলের অস্তিত্ব আছে কি না তা পরীক্ষা না করে ফেলে দেওয়া যেতে পারে। নিম্নলিখিত ড্রপ স্টেটমেন্টগুলি 'book_borrow_info' টেবিলটি মুছে দেয় এবং 'টেবিল দেখান' বিবৃতিটি সার্ভারে টেবিলটি বিদ্যমান কিনা তা পরীক্ষা করে।
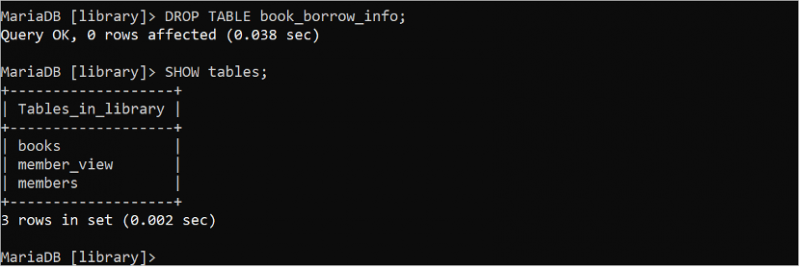
ড্রপ টেবিল বই_ধার_তথ্য;দেখান টেবিল ;
আউটপুট দেখায় যে 'book_borrow_info' টেবিলটি বাদ দেওয়া হয়েছে।
টেবিলটি সার্ভারে বিদ্যমান কিনা তা পরীক্ষা করার পরে বাদ দেওয়া যেতে পারে। এই টেবিলগুলি সার্ভারে বিদ্যমান থাকলে বই এবং সদস্য টেবিল মুছে ফেলার জন্য নিম্নলিখিত DROP বিবৃতিটি চালান। এর পরে, 'সারণীগুলি দেখান' বিবৃতিটি সার্ভারে টেবিলগুলি বিদ্যমান কিনা তা পরীক্ষা করে।
ড্রপ টেবিল IF বিদ্যমান বই , সদস্য;দেখান টেবিল ;
নিম্নলিখিত আউটপুট দেখায় যে টেবিলগুলি সার্ভার থেকে মুছে ফেলা হয়েছে:

ডাটাবেস ফেলে দিন
সার্ভার থেকে 'লাইব্রেরি' ডাটাবেস মুছে ফেলার জন্য নিম্নলিখিত SQL বিবৃতিটি চালান:
ড্রপ তথ্যশালা গ্রন্থাগার;আউটপুট দেখায় যে ডাটাবেস ড্রপ করা হয়েছে।

উপসংহার
মারিয়াডিবি সার্ভারের ডাটাবেস তৈরি, অ্যাক্সেস, পরিবর্তন এবং মুছে ফেলার জন্য সর্বাধিক ব্যবহৃত এসকিউএল কোয়েরি উদাহরণগুলি একটি ডাটাবেস এবং তিনটি টেবিল তৈরি করে এই টিউটোরিয়ালে দেখানো হয়েছে। নতুন ডাটাবেস ব্যবহারকারীকে SQL বেসিকগুলি সঠিকভাবে শিখতে সাহায্য করার জন্য বিভিন্ন SQL স্টেটমেন্টের ব্যবহার খুব সহজ উদাহরণ দিয়ে ব্যাখ্যা করা হয়েছে। জটিল প্রশ্নের ব্যবহার এখানে বাদ দেওয়া হয়েছে। নতুন ডাটাবেস ব্যবহারকারীরা এই টিউটোরিয়ালটি সঠিকভাবে পড়ার পরে যে কোনও ডাটাবেসের সাথে কাজ শুরু করতে সক্ষম হবেন।