ডুপ্লিকেট ডেটা প্রায়ই বিভ্রান্তি, ত্রুটি এবং তির্যক অন্তর্দৃষ্টির দিকে নিয়ে যেতে পারে। সৌভাগ্যবশত, এই অপ্রয়োজনীয় এন্ট্রি সনাক্তকরণ এবং অপসারণের কাজকে সহজ করার জন্য Google পত্রক আমাদেরকে অনেক টুল এবং কৌশল প্রদান করে। বেসিক সেল তুলনা থেকে শুরু করে উন্নত সূত্র-ভিত্তিক পন্থা, আপনি বিশৃঙ্খল শীটগুলিকে সংগঠিত, মূল্যবান সম্পদে রূপান্তর করতে সজ্জিত হবেন।
আপনি গ্রাহক তালিকা, সমীক্ষার ফলাফল বা অন্য কোনও ডেটাসেট পরিচালনা করছেন না কেন, ডুপ্লিকেট এন্ট্রিগুলি বাদ দেওয়া নির্ভরযোগ্য বিশ্লেষণ এবং সিদ্ধান্ত গ্রহণের দিকে একটি মৌলিক পদক্ষেপ।
এই নির্দেশিকায়, আমরা আপনাকে ডুপ্লিকেট মান সনাক্ত করতে এবং অপসারণ করার অনুমতি দেওয়ার জন্য দুটি পদ্ধতির সন্ধান করব।
টেবিল তৈরি
আমরা প্রথমে Google পত্রকগুলিতে একটি টেবিল তৈরি করেছি, যা এই নিবন্ধে পরে উদাহরণগুলিতে ব্যবহার করা হবে। এই টেবিলে 3টি কলাম রয়েছে: কলাম A, শিরোনাম 'নাম' সহ, স্টোরের নাম; কলাম B-এর শিরোনাম আছে 'বয়স', যা মানুষের বয়স ধরে রাখে; এবং সবশেষে, কলাম সি, শিরোনাম “শহর”-এ শহর রয়েছে। যদি আমরা লক্ষ্য করি, এই টেবিলের কিছু এন্ট্রি নকল করা হয়েছে, যেমন 'জন' এবং 'সারা' এর এন্ট্রি।
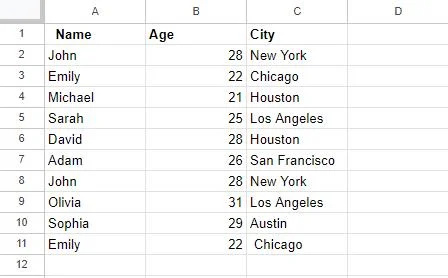
আমরা এই টেবিলে বিভিন্ন পদ্ধতির সাথে এই ডুপ্লিকেট মানগুলি সরাতে কাজ করব।
পদ্ধতি 1: Google পত্রকগুলিতে 'সদৃশগুলি সরান' বৈশিষ্ট্যটি ব্যবহার করে৷
আমরা এখানে আলোচনা করা প্রথম পদ্ধতিটি হল Google পত্রকের 'সদৃশগুলি সরান' বৈশিষ্ট্যটি ব্যবহার করে সদৃশ মানগুলি সরানো৷ এই পদ্ধতিটি স্থায়ীভাবে ঘরের নির্বাচিত পরিসর থেকে সদৃশ এন্ট্রি মুছে ফেলবে।
এই পদ্ধতিটি প্রদর্শন করার জন্য, আমরা আবার উপরে উত্পন্ন টেবিল বিবেচনা করব।
এই পদ্ধতিতে কাজ শুরু করার জন্য, প্রথমে, হেডার সহ আমাদের ডেটা সম্বলিত সমগ্র পরিসরটি নির্বাচন করতে হবে। এই পরিস্থিতিতে, আমরা ঘর নির্বাচন করেছি A1:C11 .
গুগল শীট উইন্ডোর শীর্ষে, আপনি বিভিন্ন মেনু সহ একটি নেভিগেশন বার দেখতে পাবেন। নেভিগেশন বারে 'ডেটা' বিকল্পটি সনাক্ত করুন এবং ক্লিক করুন।
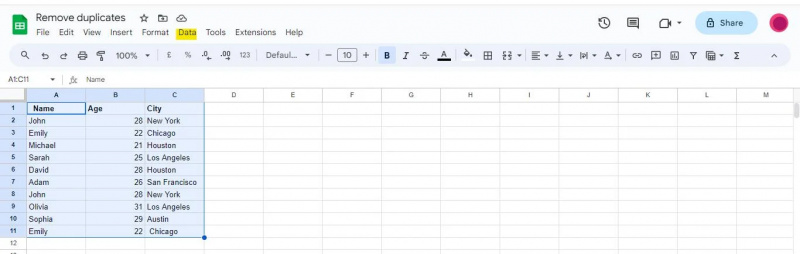
আপনি যখন 'ডেটা' বিকল্পে ক্লিক করবেন তখন একটি ড্রপডাউন মেনু প্রদর্শিত হবে, যা আপনাকে বিভিন্ন ডেটা-সম্পর্কিত সরঞ্জাম এবং ফাংশনগুলির সাথে উপস্থাপন করবে যা আপনার ডেটা বিশ্লেষণ, পরিষ্কার এবং ম্যানিপুলেট করতে ব্যবহার করা যেতে পারে।
এই উদাহরণের জন্য, 'ডেটা ক্লিনআপ' বিকল্পে নেভিগেট করার জন্য আমাদের 'ডেটা' মেনু অ্যাক্সেস করতে হবে, যার মধ্যে 'সদৃশগুলি সরান' বৈশিষ্ট্য অন্তর্ভুক্ত রয়েছে।
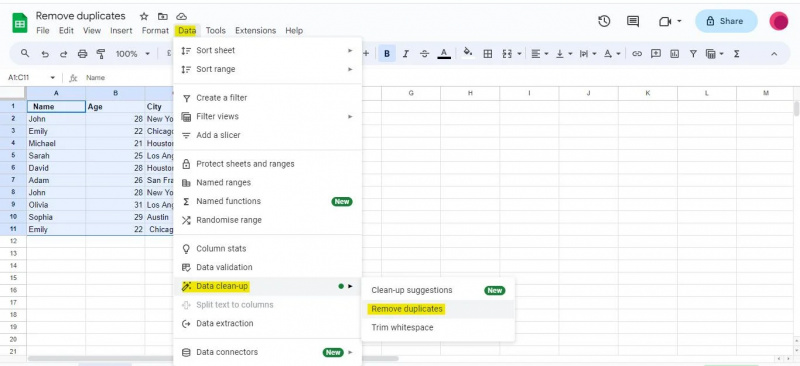
আমরা 'সদৃশগুলি সরান' ডায়ালগ বক্সটি অ্যাক্সেস করার পরে, আমাদের ডেটাসেটে কলামগুলির একটি তালিকা উপস্থাপন করা হবে৷ এই কলামগুলির উপর ভিত্তি করে, সদৃশগুলি খুঁজে পাওয়া যাবে এবং সরানো হবে৷ ডুপ্লিকেট শনাক্ত করার জন্য আমরা কোন কলাম ব্যবহার করতে চাই তার উপর নির্ভর করে আমরা ডায়ালগ বক্সে সংশ্লিষ্ট চেকবক্সগুলি চিহ্নিত করব।
আমাদের উদাহরণে, আমাদের তিনটি কলাম আছে: 'নাম,' 'বয়স' এবং 'শহর।' যেহেতু আমরা তিনটি কলামের উপর ভিত্তি করে ডুপ্লিকেট সনাক্ত করতে চাই, আমরা তিনটি চেকবক্সে টিক দিয়েছি। তা ছাড়া, আপনার টেবিলে হেডার থাকলে আপনাকে 'ডেটা আছে হেডার সারি' চেকবক্সটি চেক করতে হবে। যেহেতু আমাদের উপরে দেওয়া টেবিলে হেডার আছে, আমরা 'ডেটা আছে হেডার সারি' চেকবক্স চেক করেছি।
একবার আমরা সদৃশ শনাক্ত করার জন্য কলামগুলি নির্বাচন করার পরে, আমরা আমাদের ডেটাসেট থেকে সেই সদৃশগুলি সরাতে এগিয়ে যেতে পারি।
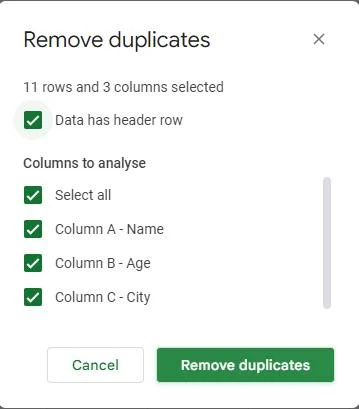
আপনি 'সদৃশগুলি সরান' ডায়ালগ বক্সের নীচে একটি বোতাম পাবেন যা লেবেলযুক্ত 'ডুপ্লিকেটগুলি সরান'। এই বোতামে ক্লিক করুন।
'ডুপ্লিকেটগুলি সরান' ক্লিক করার পরে, Google পত্রক আপনার অনুরোধ প্রক্রিয়া করবে৷ কলামগুলি স্ক্যান করা হবে, এবং সেই কলামগুলির ডুপ্লিকেট মান সহ যেকোনো সারি মুছে ফেলা হবে, সফলভাবে সদৃশগুলি মুছে ফেলা হবে৷
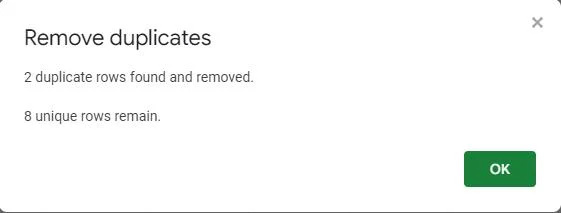
একটি পপ-আপ স্ক্রিন নিশ্চিত করে যে ডুপ্লিকেট মানগুলি টেবিল থেকে সরানো হয়েছে। এটি দেখায় যে দুটি সদৃশ সারি পাওয়া গেছে এবং সরানো হয়েছে, আটটি অনন্য এন্ট্রি সহ টেবিলটি রেখে গেছে।
'সদৃশ সরান' বৈশিষ্ট্যটি ব্যবহার করার পরে, আমাদের টেবিলটি নিম্নরূপ আপডেট করা হয়েছে:
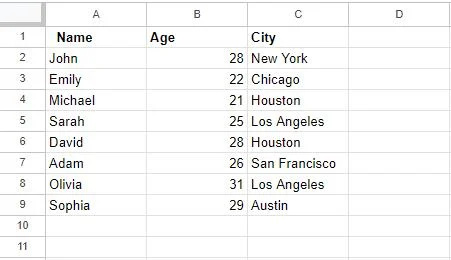
এখানে বিবেচনা করার জন্য একটি গুরুত্বপূর্ণ নোট হল যে এই বৈশিষ্ট্যটি ব্যবহার করে সদৃশগুলি সরানো একটি স্থায়ী পদক্ষেপ। আপনার ডেটাসেট থেকে ডুপ্লিকেট সারিগুলি মুছে ফেলা হবে এবং আপনার ডেটা ব্যাকআপ না থাকলে আপনি এই ক্রিয়াটিকে পূর্বাবস্থায় ফিরিয়ে আনতে পারবেন না৷ সুতরাং, আপনার নির্বাচনকে দুবার পরীক্ষা করে ডুপ্লিকেটগুলি খুঁজে পেতে আপনি সঠিক কলামগুলি বেছে নিয়েছেন তা নিশ্চিত করুন৷
পদ্ধতি 2: সদৃশ অপসারণ করতে ইউনিক ফাংশন ব্যবহার করে
আমরা এখানে আলোচনা করব দ্বিতীয় পদ্ধতি ব্যবহার করে অনন্য Google শীটে ফাংশন। দ্য অনন্য ফাংশন একটি নির্দিষ্ট পরিসর বা ডেটার কলাম থেকে স্বতন্ত্র মান উদ্ধার করে। যদিও এটি সরাসরি মূল ডেটা থেকে সদৃশগুলি সরিয়ে দেয় না, এটি অনন্য মানগুলির একটি তালিকা তৈরি করে যা আপনি ডুপ্লিকেট ছাড়াই ডেটা রূপান্তর বা বিশ্লেষণের জন্য ব্যবহার করতে পারেন।
এই পদ্ধতিটি বোঝার জন্য একটি উদাহরণ তৈরি করা যাক।
আমরা এই টিউটোরিয়ালের প্রাথমিক অংশে তৈরি করা টেবিলটি ব্যবহার করব। আমরা ইতিমধ্যে জানি, টেবিলে কিছু ডেটা রয়েছে যা নকল করা হয়েছে। সুতরাং, আমরা একটি ঘর বেছে নিয়েছি, “E2” লিখতে অনন্য মধ্যে সূত্র আমরা যে সূত্রটি লিখেছি তা নিম্নরূপ:
=অনন্য(A2:A11)
Google পত্রকগুলিতে ব্যবহার করা হলে, অনন্য সূত্রটি একটি পৃথক কলামে অনন্য মানগুলি পুনরুদ্ধার করে৷ সুতরাং, আমরা সেল থেকে একটি পরিসীমা সহ এই সূত্রটি প্রদান করেছি A2 প্রতি A11 , যা কলাম A-তে প্রয়োগ করা হবে। সুতরাং, এই সূত্রটি কলাম থেকে অনন্য মান বের করে ক এবং তাদের কলামে প্রদর্শন করে যেখানে সূত্রটি লেখা হয়েছে।
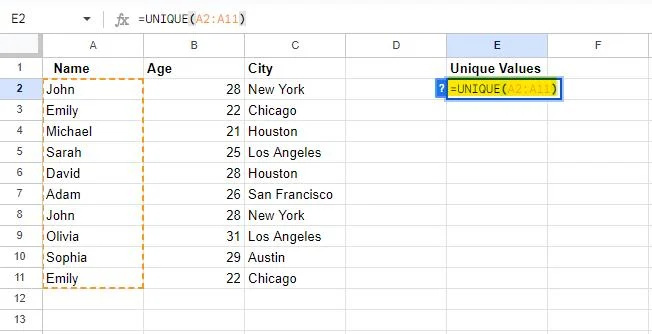
আপনি এন্টার কী টিপলে সূত্রটি নির্ধারিত পরিসরে প্রয়োগ করা হবে।
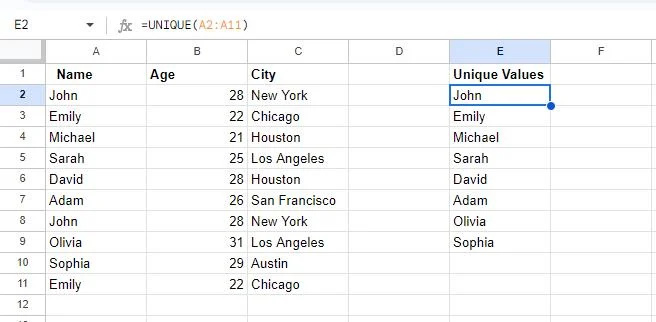
এই স্ন্যাপশটে, আমরা দেখতে পাচ্ছি যে দুটি ঘর ফাঁকা। এর কারণ হল টেবিলে দুটি মান ডুপ্লিকেট করা হয়েছে, যথা, জন এবং এমিলি। দ্য অনন্য ফাংশন শুধুমাত্র প্রতিটি মানের একটি একক উদাহরণ প্রদর্শন করে।
এই পদ্ধতিটি নির্দিষ্ট কলাম থেকে সরাসরি ডুপ্লিকেট করা মানগুলিকে সরিয়ে দেয়নি কিন্তু আমাদেরকে সেই কলামের অনন্য এন্ট্রি প্রদান করার জন্য অন্য একটি কলাম তৈরি করেছে, সদৃশগুলি বাদ দিয়ে।
উপসংহার
Google পত্রকগুলিতে সদৃশগুলি সরানো ডেটা বিশ্লেষণের জন্য একটি উপকারী পদ্ধতি৷ এই নির্দেশিকা দুটি পদ্ধতি প্রদর্শন করেছে যা আপনাকে সহজেই আপনার ডেটা থেকে ডুপ্লিকেট এন্ট্রিগুলি সরাতে সক্ষম করে। প্রথম পদ্ধতিটি ডুপ্লিকেট বৈশিষ্ট্যটি সরাতে Google পত্রকের ব্যবহার ব্যাখ্যা করেছে। এই পদ্ধতিটি নির্দিষ্ট সেল পরিসীমা স্ক্যান করে এবং সদৃশগুলিকে মুছে দেয়। অন্য যে পদ্ধতিটি আমরা আলোচনা করেছি তা হল ডুপ্লিকেট মান পুনরুদ্ধারের জন্য সূত্রটি ব্যবহার করা। যদিও এটি সরাসরি পরিসর থেকে সদৃশগুলি সরিয়ে দেয় না, এটি পরিবর্তে একটি নতুন কলামে অনন্য মানগুলি প্রদর্শন করে।