C# এ XML পড়া
C# এ একটি XML ফাইল পড়ার বিভিন্ন উপায় রয়েছে এবং প্রতিটি পদ্ধতির সুবিধা এবং অসুবিধা রয়েছে এবং পছন্দটি প্রকল্পের প্রয়োজনীয়তার উপর নির্ভর করে। নীচে C# এ একটি XML ফাইল পড়ার কিছু উপায় রয়েছে:
- XmlDocument ব্যবহার করে
- XDocument ব্যবহার করে
- XmlReader ব্যবহার করে
- XML থেকে LINQ ব্যবহার করা
- XPath ব্যবহার করে
এখানে XML ফাইলের বিষয়বস্তু যা আমি তৈরি করেছি এবং আগামী পদ্ধতিতে প্রদর্শনের জন্য ব্যবহার করা হবে:
< xml সংস্করণ = '1.0' এনকোডিং = 'UTF-8' ? >
< কর্মচারী >
< কর্মচারী >
< আইডি > 1 আইডি >
< নাম > স্যাম বোশ নাম >
< বিভাগ > মার্কেটিং বিভাগ >
< বেতন > 50000 বেতন >
কর্মচারী >
< কর্মচারী >
< আইডি > 2 আইডি >
< নাম > জানি দই নাম >
< বিভাগ > অর্থায়ন বিভাগ >
< বেতন > 60000 বেতন >
কর্মচারী >
< কর্মচারী >
< আইডি > 3 আইডি >
< নাম > জেমস নাম >
< বিভাগ > মানব সম্পদ বিভাগ >
< বেতন > 70000 বেতন >
কর্মচারী >
কর্মচারী >
1: XmlDocument ব্যবহার করা
C# এ একটি XML ফাইল পড়ার জন্য, আপনি XmlDocument ক্লাস বা XDocument ক্লাস ব্যবহার করতে পারেন, উভয়ই System.Xml নামস্থানের অংশ। XmlDocument ক্লাস XML পড়ার জন্য একটি DOM (ডকুমেন্ট অবজেক্ট মডেল) পদ্ধতি প্রদান করে, যেখানে XDocument ক্লাস একটি LINQ (ভাষা-ইন্টিগ্রেটেড কোয়েরি) পদ্ধতি প্রদান করে। এখানে একটি XML ফাইল পড়ার জন্য XmlDocument ক্লাস ব্যবহার করার একটি উদাহরণ রয়েছে:
সিস্টেম ব্যবহার করে;
System.Xml ব্যবহার করে;
ক্লাস প্রোগ্রাম
{
স্ট্যাটিক শূন্যতা প্রধান ( স্ট্রিং [ ] args )
{
XmlDocument ডক = নতুন XmlDocument ( ) ;
ডক.লোড ( 'employees.xml' ) ;
XmlNodeList nodes = doc.DocumentElement.SelectNodes ( '/কর্মচারী/কর্মচারী' ) ;
প্রতিটির জন্য ( XmlNode নোড ভিতরে নোড )
{
স্ট্রিং আইডি = node.SelectSingleNode ( 'আইডি' ) অভ্যন্তরীণ পাঠ্য;
string name = node.SelectSingleNode ( 'নাম' ) অভ্যন্তরীণ পাঠ্য;
string Department = node.SelectSingleNode ( 'বিভাগ' ) অভ্যন্তরীণ পাঠ্য;
string salary = node.SelectSingleNode ( 'বেতন' ) অভ্যন্তরীণ পাঠ্য;
Console.WriteLine ( 'আইডি: {0}, নাম: {1}, বিভাগ: {2}, বেতন: {3}' , আইডি , নাম, বিভাগ, বেতন ) ;
}
}
}
এই কোডটি XML ফাইল লোড করার জন্য XmlDocument ক্লাস এবং কর্মচারী নোডগুলির একটি তালিকা পুনরুদ্ধার করতে SelectNodes পদ্ধতি ব্যবহার করে। তারপর, প্রতিটি কর্মচারী নোডের জন্য, এটি আইডি, নাম, বিভাগ এবং বেতন চাইল্ড নোডের মান পুনরুদ্ধার করতে SelectSingleNode পদ্ধতি ব্যবহার করে এবং Console.WriteLine ব্যবহার করে সেগুলি প্রদর্শন করে:

2: XDocument ব্যবহার করা
বিকল্পভাবে, আপনি LINQ পদ্ধতি ব্যবহার করে একটি XML ফাইল পড়ার জন্য XDocument ক্লাসটিও ব্যবহার করতে পারেন, এবং নীচের কোডটি ব্যাখ্যা করে যে এটি কীভাবে করা যায়:
সিস্টেম ব্যবহার করে;ক্লাস প্রোগ্রাম
{
স্ট্যাটিক শূন্যতা প্রধান ( স্ট্রিং [ ] args )
{
XDocument doc = XDocument.Load ( 'employees.xml' ) ;
প্রতিটির জন্য ( XElement উপাদান ভিতরে ডক. বংশধর ( 'কর্মচারী' ) )
{
int আইডি = int.Parse ( উপাদান।উপাদান ( 'আইডি' ) .মান ) ;
স্ট্রিং নাম = উপাদান।এলিমেন্ট ( 'নাম' ) মান;
string Department = element.Element ( 'বিভাগ' ) মান;
int বেতন = int.Parse ( উপাদান।উপাদান ( 'বেতন' ) .মান ) ;
Console.WriteLine ( $ 'আইডি: {id}, নাম: {name}, বিভাগ: {department}, বেতন: {salary}' ) ;
}
}
}
XML ফাইলটি XDocument.Load পদ্ধতি ব্যবহার করে একটি XDocument অবজেক্টে লোড করা হয়। XML ফাইলের 'কর্মচারী' উপাদানগুলি ডিসেন্ডেন্ট কৌশল ব্যবহার করে সমস্ত পুনরুদ্ধার করা হয়। প্রতিটি উপাদানের জন্য, এর শিশু উপাদানগুলি এলিমেন্ট পদ্ধতি ব্যবহার করে অ্যাক্সেস করা হয়, এবং মান বৈশিষ্ট্য ব্যবহার করে তাদের মানগুলি বের করা হয়। অবশেষে, নিষ্কাশিত ডেটা কনসোলে প্রিন্ট করা হয়।
মনে রাখবেন যে XDocument System.Xml.Linq নামস্থানের অন্তর্গত, তাই আপনাকে আপনার C# ফাইলের শীর্ষে নিম্নলিখিত ব্যবহার করে বিবৃতি অন্তর্ভুক্ত করতে হবে

3: XmlReader ব্যবহার করা
XmlReader হল C# এ একটি XML ফাইল পড়ার একটি দ্রুত এবং কার্যকর উপায়। এটি ক্রমানুসারে ফাইলটি পড়ে, যার মানে এটি একটি সময়ে শুধুমাত্র একটি নোড লোড করে, এটি বড় XML ফাইলগুলির সাথে কাজ করার জন্য আদর্শ করে তোলে যা অন্যথায় মেমরিতে পরিচালনা করা কঠিন হবে।
সিস্টেম ব্যবহার করে;System.Xml ব্যবহার করে;
ক্লাস প্রোগ্রাম
{
স্ট্যাটিক শূন্যতা প্রধান ( স্ট্রিং [ ] args )
{
ব্যবহার ( XmlReader reader = XmlReader.Create ( 'employees.xml' ) )
{
যখন ( পাঠক।পড়ুন ( ) )
{
যদি ( reader.NodeType == XmlNodeType.Element && পাঠক। নাম == 'কর্মচারী' )
{
Console.WriteLine ( 'আইডি:' + পাঠক।GetAttribute ( 'আইডি' ) ) ;
reader.ReadToDescendant ( 'নাম' ) ;
Console.WriteLine ( 'নাম:' + reader.ReadElementContentAsString ( ) ) ;
reader.ReadToNextSibling ( 'বিভাগ' ) ;
Console.WriteLine ( 'বিভাগ:' + reader.ReadElementContentAsString ( ) ) ;
reader.ReadToNextSibling ( 'বেতন' ) ;
Console.WriteLine ( 'বেতন:' + reader.ReadElementContentAsString ( ) ) ;
}
}
}
}
}
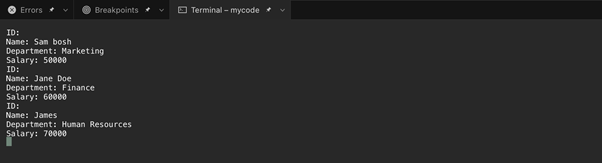
এই উদাহরণে, আমরা XmlReader ব্যবহার করি। XmlReader-এর একটি উদাহরণ তৈরি করার জন্য একটি পদ্ধতি তৈরি করুন এবং একটি প্যারামিটার হিসাবে XML ফাইল পাথ পাস করুন। তারপরে আমরা XmlReader-এর Read পদ্ধতি ব্যবহার করে নোড দ্বারা XML ফাইল নোডের মাধ্যমে পড়ার জন্য একটি while লুপ ব্যবহার করি।
লুপের ভিতরে, আমরা প্রথমে XmlReader-এর NodeType এবং Name বৈশিষ্ট্যগুলি ব্যবহার করে বর্তমান নোডটি একটি কর্মচারী উপাদান কিনা তা পরীক্ষা করি। যদি তাই হয়, আমরা id অ্যাট্রিবিউটের মান পুনরুদ্ধার করতে GetAttribute পদ্ধতি ব্যবহার করি।
এর পরে, আমরা রিডারকে কর্মচারী উপাদানের ভিতরে নাম উপাদানে নিয়ে যেতে ReadToDescendant পদ্ধতি ব্যবহার করি। নাম উপাদানের মান তারপর ReadElementContentAsString ফাংশন ব্যবহার করে প্রাপ্ত করা হয়।
একইভাবে, আমরা ReadToNextSibling পদ্ধতি ব্যবহার করি পাঠককে পরবর্তী ভাইবোন উপাদানে নিয়ে যেতে এবং বিভাগ এবং বেতন উপাদানের মান পেতে।
অবশেষে, আমরা XML ফাইলটি পড়া শেষ করার পরে XmlReader অবজেক্টটি সঠিকভাবে নিষ্পত্তি করা হয়েছে তা নিশ্চিত করতে আমরা ব্লক ব্যবহার করি:
4: XML থেকে LINQ
C# এ LINQ থেকে XML ব্যবহার করে একটি XML ফাইল পড়া XML ডেটা অ্যাক্সেস এবং ম্যানিপুলেট করার একটি শক্তিশালী উপায়। LINQ থেকে XML হল LINQ প্রযুক্তির একটি উপাদান যা XML ডেটা নিয়ে কাজ করার জন্য একটি সহজ এবং দক্ষ API প্রদান করে।
সিস্টেম ব্যবহার করে;System.Linq ব্যবহার করে;
System.Xml.Linq ব্যবহার করে;
ক্লাস প্রোগ্রাম
{
স্ট্যাটিক শূন্যতা প্রধান ( স্ট্রিং [ ] args )
{
XDocument doc = XDocument.Load ( 'employees.xml' ) ;
var কর্মচারী = ই থেকে ভিতরে ডক. বংশধর ( 'কর্মচারী' )
নির্বাচন করুন নতুন
{
Id = e.Element ( 'আইডি' ) মান,
নাম = e.Element ( 'নাম' ) মান,
বিভাগ = e.Element ( 'বিভাগ' ) মান,
বেতন = e.Element ( 'বেতন' ) .মান
} ;
প্রতিটির জন্য ( var কর্মচারী ভিতরে কর্মচারী )
{
Console.WriteLine ( $ 'Id: {employee.Id}, Name: {employee.Name}, Department: {employee.Department}, বেতন: {employee.Salary}' ) ;
}
}
}
এই কোডে, আমরা প্রথমে XDocument.Load() পদ্ধতি ব্যবহার করে XML ফাইল লোড করি। তারপর, আমরা XML ডেটা জিজ্ঞাসা করতে এবং প্রতিটি কর্মচারী উপাদানের জন্য আইডি, নাম, বিভাগ এবং বেতন উপাদান নির্বাচন করতে LINQ থেকে XML ব্যবহার করি। আমরা এই ডেটাটিকে একটি বেনামী টাইপে সঞ্চয় করি এবং তারপরে কর্মীদের তথ্য কনসোলে প্রিন্ট করতে ফলাফলগুলি লুপ করি৷

5: XPath ব্যবহার করা
XPath হল একটি ক্যোয়ারী ল্যাঙ্গুয়েজ যা নির্দিষ্ট উপাদান, গুণাবলী এবং নোডগুলি সনাক্ত করতে একটি XML নথির মাধ্যমে নেভিগেট করতে ব্যবহৃত হয়। এটি একটি XML নথিতে তথ্য অনুসন্ধান এবং ফিল্টার করার জন্য একটি কার্যকর টুল। C# এ, আমরা এক্সএমএল ফাইলগুলি থেকে ডেটা পড়তে এবং বের করতে XPath ভাষা ব্যবহার করতে পারি।
সিস্টেম ব্যবহার করে;System.Xml.XPath ব্যবহার করে;
System.Xml ব্যবহার করে;
ক্লাস প্রোগ্রাম
{
স্ট্যাটিক শূন্যতা প্রধান ( স্ট্রিং [ ] args )
{
XmlDocument ডক = নতুন XmlDocument ( ) ;
ডক.লোড ( 'employees.xml' ) ;
// নথি থেকে একটি XPathNavigator তৈরি করুন
XPathNavigator nav = doc.CreateNavigator ( ) ;
// XPath এক্সপ্রেশন কম্পাইল করুন
XPathExpression এক্সপ্রেস = nav.কম্পাইল ( '/কর্মচারী/কর্মচারী/নাম' ) ;
// অভিব্যক্তি মূল্যায়ন করুন এবং ফলাফলের মাধ্যমে পুনরাবৃত্তি করুন
XPathNodeIterator পুনরাবৃত্তিকারী = nav.Select ( এক্সপ্রেস ) ;
যখন ( iterator.MoveNext ( ) )
{
Console.WriteLine ( পুনরাবৃত্তিকারী।বর্তমান।মান ) ;
}
}
}
এই কোডটি একটি XmlDocument ব্যবহার করে 'employees.xml' ফাইল লোড করে, নথি থেকে একটি XPathNavigator তৈরি করে এবং

বিঃদ্রঃ: XPath ব্যবহার করা একটি XML নথি থেকে উপাদান এবং গুণাবলী নির্বাচন করার একটি শক্তিশালী এবং নমনীয় উপায় হতে পারে, তবে এটি আমাদের আলোচনা করা অন্যান্য পদ্ধতির তুলনায় আরও জটিল হতে পারে।
উপসংহার
XmlDocument ক্লাস ব্যবহার করা সম্পূর্ণ DOM ম্যানিপুলেশন ক্ষমতা প্রদান করে, তবে এটি অন্যান্য পদ্ধতির তুলনায় ধীর এবং আরও মেমরি-নিবিড় হতে পারে। XmlReader ক্লাসটি বড় XML ফাইল পড়ার জন্য একটি ভাল বিকল্প, কারণ এটি একটি দ্রুত, শুধুমাত্র ফরোয়ার্ড এবং নন-ক্যাশড স্ট্রীম-ভিত্তিক পদ্ধতি প্রদান করে। XDocument ক্লাস একটি সহজ এবং আরও সংক্ষিপ্ত সিনট্যাক্স প্রদান করে, কিন্তু এটি XmlReader এর মত পারফরম্যান্ট নাও হতে পারে। উপরন্তু, LINQ থেকে XML এবং XPath পদ্ধতিগুলি একটি XML ফাইল থেকে নির্দিষ্ট ডেটা বের করার জন্য শক্তিশালী কোয়েরি করার ক্ষমতা প্রদান করে।