মঙ্গোডিবিতে গ্রুপ অ্যাগ্রিগেশন কীভাবে কাজ করে?
$group অপারেটরটি নির্দিষ্ট _id এক্সপ্রেশন অনুসারে ইনপুট নথিগুলিকে গোষ্ঠীবদ্ধ করতে ব্যবহার করা উচিত। এটি প্রতিটি পৃথক গ্রুপের জন্য মোট মান সহ একটি একক নথি প্রদান করা উচিত। বাস্তবায়নের সাথে শুরু করার জন্য, আমরা MongoDB-তে 'বই' সংগ্রহ তৈরি করেছি। 'বই' সংগ্রহ তৈরি করার পরে, আমরা বিভিন্ন ক্ষেত্রের সাথে যুক্ত নথিগুলি সন্নিবেশ করেছি। নথিগুলি সংগ্রহে insertMany() পদ্ধতির মাধ্যমে ঢোকানো হয় কারণ অনুসন্ধান চালানোর জন্য নীচে দেখানো হয়েছে৷
>db.Books.insertMany([{
_id:1,
শিরোনাম: 'আন্না কারেনিনা',
মূল্য: 290,
বছর: 1879,
অর্ডার_স্ট্যাটাস: 'ইন-স্টক',
লেখক: {
'নাম':'লিও টলস্টয়'
}
},
{
_id:2,
শিরোনাম: 'একটি মকিংবার্ডকে হত্যা করতে',
মূল্য: 500,
বছর: 1960,
অর্ডার_স্ট্যাটাস: 'আউট অফ স্টক',
লেখক: {
'নাম':'হার্পার লি'
}
},
{
_id:3,
শিরোনাম: 'অদৃশ্য মানুষ',
মূল্য: 312,
বছর: 1953,
অর্ডার_স্ট্যাটাস: 'ইন-স্টক',
লেখক: {
'নাম':'রালফ এলিসন'
}
},
{
_id:4,
শিরোনাম: 'প্রিয়',
মূল্য: 370,
বছর: 1873,
অর্ডার_স্ট্যাটাস: 'আউট_অফ_স্টক',
লেখক: {
'নাম':'টনি মরিসন'
}
},
{
_id:5,
শিরোনাম: 'থিংস ফল অ্যাপার্ট',
মূল্য: 200,
বছর: 1958,
অর্ডার_স্ট্যাটাস: 'ইন-স্টক',
লেখক: {
'নাম':'চিনুয়া আচেবে'
}
},
{
_id:6,
শিরোনাম: 'রঙ বেগুনি',
মূল্য: 510,
বছর: 1982,
অর্ডার_স্ট্যাটাস: 'আউট অফ স্টক',
লেখক: {
'নাম':'এলিস ওয়াকার'
}
}
])
নথিগুলি সফলভাবে 'বই' সংগ্রহে কোনো ত্রুটির সম্মুখীন না হয়ে সংরক্ষণ করা হয়েছে কারণ আউটপুটটি 'সত্য' হিসাবে স্বীকৃত। এখন, আমরা '$গ্রুপ' সমষ্টি সম্পাদনের জন্য 'বই' সংগ্রহের এই নথিগুলি ব্যবহার করতে যাচ্ছি।

উদাহরণ # 1: $গ্রুপ অ্যাগ্রিগেশনের ব্যবহার
$group সমষ্টির সহজ ব্যবহার এখানে প্রদর্শিত হয়েছে। সমষ্টিগত ক্যোয়ারী প্রথমে '$group' অপারেটরকে ইনপুট করে তারপর '$group' অপারেটর গ্রুপ করা নথি তৈরি করতে এক্সপ্রেশনগুলি নেয়।
>db.Books.aggregate([
{ $group:{ _id:'$author.name'} }
])
$group অপারেটরের উপরের ক্যোয়ারীটি সমস্ত ইনপুট নথির জন্য মোট মান গণনা করার জন্য '_id' ক্ষেত্রের সাথে নির্দিষ্ট করা হয়েছে। তারপর, '_id' ক্ষেত্রটি '$author.name' এর সাথে বরাদ্দ করা হয় যা '_id' ক্ষেত্রে একটি ভিন্ন গ্রুপ গঠন করে। $author.name-এর পৃথক মান ফেরত দেওয়া হবে কারণ আমরা কোনো জমা করা মান গণনা করি না। $group সমষ্টিগত প্রশ্নের সঞ্চালনের জন্য নিম্নলিখিত আউটপুট রয়েছে। _id ক্ষেত্রে author.names এর মান আছে।

উদাহরণ # 2: $পুশ অ্যাকুমুলেটরের সাথে $গ্রুপ অ্যাগ্রিগেশনের ব্যবহার
$গ্রুপ অ্যাগ্রিগেশনের উদাহরণে উপরে উল্লিখিত কোনো সঞ্চয়কারী ব্যবহার করা হয়। কিন্তু আমরা $গ্রুপ এগ্রিগেশনে অ্যাকুমুলেটর ব্যবহার করতে পারি। সঞ্চয়কারী অপারেটরগুলি হল যেগুলি ইনপুট নথি ক্ষেত্রে ব্যবহার করা হয় যেগুলি '_id' এর অধীনে 'গ্রুপ করা' ব্যতীত। আসুন ধরে নিই যে আমরা এক্সপ্রেশনের ক্ষেত্রগুলিকে একটি অ্যারেতে পুশ করতে চাই তারপর '$পুশ' সঞ্চয়কারীকে '$গ্রুপ' অপারেটরে ডাকা হয়। উদাহরণটি আপনাকে '$গ্রুপ' এর '$পুশ' সঞ্চয়কারীকে আরও স্পষ্টভাবে বুঝতে সাহায্য করবে।
>db.Books.aggregate([
{ $গ্রুপ : { _id : '$_id', বছর: { $push: '$year' } }
]
সুন্দর();
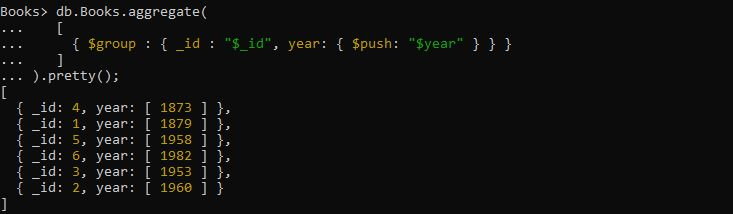
এখানে, আমরা অ্যারেতে প্রদত্ত বইগুলির প্রকাশিত বছরের তারিখটি গ্রুপ করতে চাই। এটি সম্পন্ন করার জন্য উপরের প্রশ্নটি প্রয়োগ করা উচিত। অ্যাগ্রিগেশন কোয়েরিটি এক্সপ্রেশনের সাথে প্রদান করা হয় যেখানে '$group' অপারেটর $push অ্যাকুমুলেটর ব্যবহার করে গ্রুপ বছর পেতে ফিল্ড এক্সপ্রেশন '_id' এবং 'year' ফিল্ড এক্সপ্রেশন নেয়। এই নির্দিষ্ট ক্যোয়ারী থেকে পুনরুদ্ধার করা আউটপুট বছরের ক্ষেত্রগুলির অ্যারে তৈরি করে এবং এর ভিতরে ফিরে আসা দলবদ্ধ নথি সংরক্ষণ করে।
উদাহরণ # 3: '$min' সঞ্চয়কারীর সাথে $গ্রুপ অ্যাগ্রিগেশনের ব্যবহার
এর পরে, আমাদের কাছে '$min' সঞ্চয়কারী রয়েছে যা সংগ্রহের প্রতিটি নথি থেকে ন্যূনতম ম্যাচিং মান পেতে $গ্রুপ অ্যাগ্রিগেশনে ব্যবহৃত হয়। $মিন সঞ্চয়কারীর জন্য ক্যোয়ারী এক্সপ্রেশন নিচে দেওয়া হল।
>db.Books.aggregate([{
$গ্রুপ:{
_id:{
শিরোনাম: '$title',
অর্ডার_স্ট্যাটাস: '$order_status'
},
minprice:{$min: '$price'}
}
}
])
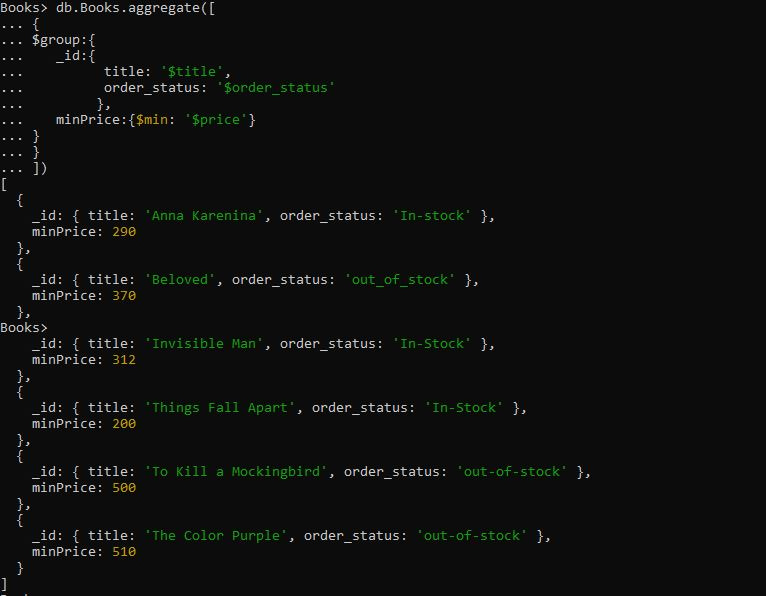
ক্যোয়ারীটিতে '$group' সমষ্টিগত অভিব্যক্তি রয়েছে যেখানে আমরা 'শিরোনাম' এবং 'order_status' ক্ষেত্রের জন্য নথিটিকে গোষ্ঠীবদ্ধ করেছি। তারপরে, আমরা $min সঞ্চয়কারী প্রদান করেছি যা দলবিহীন ক্ষেত্রগুলি থেকে ন্যূনতম মূল্যের মান পেয়ে দলিলগুলিকে গোষ্ঠীভুক্ত করে। যখন আমরা নিচে $min accumulator-এর এই ক্যোয়ারীটি চালাই, তখন এটি শিরোনাম এবং order_status অনুসারে দলবদ্ধ নথিগুলিকে একটি ক্রমানুসারে ফেরত দেয়। সর্বনিম্ন মূল্য প্রথমে প্রদর্শিত হয়, এবং নথির সর্বোচ্চ মূল্যটি সর্বশেষে রাখা হয়।
উদাহরণ # 4: $সম সঞ্চয়কারীর সাথে $গ্রুপ অ্যাগ্রিগেশন ব্যবহার করুন
$group অপারেটর ব্যবহার করে সমস্ত সংখ্যাসূচক ক্ষেত্রগুলির যোগফল পেতে, $sum অ্যাকুমুলেটর অপারেশনটি স্থাপন করা হয়। সংগ্রহের অ-সংখ্যাসূচক মানগুলি এই সঞ্চয়ক দ্বারা বিবেচনা করা হয়। উপরন্তু, আমরা $গ্রুপ এগ্রিগেশনের সাথে এখানে $match এগ্রিগেশন ব্যবহার করছি। $match একত্রীকরণ একটি নথিতে দেওয়া ক্যোয়ারী শর্তগুলিকে গ্রহণ করে এবং মিলিত নথিটিকে $group এগ্রিগেশনে পাস করে যা তারপর প্রতিটি গোষ্ঠীর জন্য নথির যোগফল প্রদান করে। $সম সঞ্চয়কারীর জন্য, প্রশ্নটি নীচে উপস্থাপন করা হয়েছে।
>db.Books.aggregate([{ $match:{ order_status:'In-stock'}},
{ $group:{ _id:'$author.name', মোট বই: { $sum:1 } }
}])
একত্রিতকরণের উপরের ক্যোয়ারী $match অপারেটর দিয়ে শুরু হয় যা সমস্ত 'order_status' এর সাথে মেলে যার স্থিতি হল 'ইন-স্টক' এবং ইনপুট হিসাবে $group-এ পাঠানো হয়। তারপর, $group অপারেটরের $sum অ্যাকুমুলেটর এক্সপ্রেশন থাকে যা স্টকের সমস্ত বইয়ের যোগফল বের করে। মনে রাখবেন যে '$sum:1' একই গ্রুপের প্রতিটি নথিতে 1 যোগ করে। এখানে আউটপুট শুধুমাত্র দুটি দলবদ্ধ নথি দেখায় যেগুলির 'অর্ডার_স্ট্যাটাস' 'ইন-স্টক' এর সাথে যুক্ত।

উদাহরণ # 5: $সার্ট অ্যাগ্রিগেশনের সাথে $গ্রুপ অ্যাগ্রিগেশন ব্যবহার করুন
এখানে $group অপারেটরটি '$sort' অপারেটরের সাথে ব্যবহৃত হয় যা দলবদ্ধ নথিগুলিকে সাজাতে ব্যবহৃত হয়। নিম্নলিখিত ক্যোয়ারী বাছাই অপারেশন তিনটি ধাপ আছে. প্রথমে হল $match পর্যায়, তারপর $group পর্যায় এবং শেষ হল $sort স্টেজ যা দলবদ্ধ নথিকে সাজায়।
>db.Books.aggregate([{ $match:{ order_status:'out-of-stock'}},
{ $group:{ _id:{ authorName :'$author.name'}, মোট বই: { $sum:1} } },
{ $sort:{ authorName:1}}
])
এখানে, আমরা মিলে যাওয়া ডকুমেন্টটি নিয়ে এসেছি যার 'অর্ডার_স্ট্যাটাস' স্টক-এর বাইরে। তারপরে, মিলিত নথিটি $group পর্যায়ে ইনপুট করা হয় যা নথিটিকে 'authorName' এবং 'totalBooks' ক্ষেত্র সহ দলবদ্ধ করে। $group এক্সপ্রেশন $sum accumulator-এর সাথে 'স্টক-এর বাইরে' বইয়ের মোট সংখ্যার সাথে যুক্ত। গোষ্ঠীবদ্ধ নথিগুলিকে তারপর $sort এক্সপ্রেশন দিয়ে ক্রমবর্ধমান ক্রম অনুসারে সাজানো হয় “1” এখানে আরোহী ক্রম নির্দেশ করে। নির্দিষ্ট ক্রমে বাছাই করা গ্রুপ নথিটি নিম্নলিখিত আউটপুটে প্রাপ্ত হয়।

উদাহরণ # 6: স্বতন্ত্র মানের জন্য $group সমষ্টি ব্যবহার করুন
একত্রিতকরণ পদ্ধতি স্বতন্ত্র আইটেমের মানগুলি বের করতে $group অপারেটর ব্যবহার করে আইটেম অনুসারে নথিগুলিকে গোষ্ঠীভুক্ত করে। আমাদের MongoDB-তে এই বিবৃতিটির প্রশ্নের অভিব্যক্তি আছে।
>db.Books.aggregate( [ { $group : { _id : '$title' } } ] ).pretty();গ্রুপ ডকুমেন্টের স্বতন্ত্র মান পেতে বই সংগ্রহে সমষ্টিগত প্রশ্ন প্রয়োগ করা হয়। এখানে $group _id এক্সপ্রেশনটি নেয় যা স্বতন্ত্র মানগুলিকে আউটপুট করে কারণ আমরা এতে 'টাইটেল' ক্ষেত্রটি ইনপুট করেছি। গ্রুপ নথির আউটপুট এই ক্যোয়ারী চালানোর পরে প্রাপ্ত হয় যার _id ক্ষেত্রের বিপরীতে শিরোনাম নামের গ্রুপ রয়েছে।

উপসংহার
মঙ্গোডিবি ডাটাবেসে ডকুমেন্টকে গ্রুপ করার জন্য $গ্রুপ অ্যাগ্রিগেশন অপারেটরের ধারণা পরিষ্কার করা গাইডটির লক্ষ্য। MongoDB সমষ্টিগত পদ্ধতি গ্রুপিং ঘটনাকে উন্নত করে। $group অপারেটরের সিনট্যাক্স কাঠামো উদাহরণ প্রোগ্রামগুলির সাথে প্রদর্শিত হয়। $গ্রুপ অপারেটরদের মৌলিক উদাহরণ ছাড়াও, আমরা এই অপারেটরকে $push, $min, $sum, এবং $match এবং $sort এর মত কিছু সঞ্চয়কারীর সাথে নিযুক্ত করেছি।