কখনও কখনও প্রদত্ত ডেটাসেট একটি একক CSV ফাইলে থাকে না। তারা সব বিভিন্ন এক্সেল শীটে আছে. আপনি ইতিমধ্যেই জানেন যে একাধিক ডেটাসেটের পরিবর্তে একটি একক ডেটাসেটে সমস্ত গণনামূলক বা প্রিপ্রসেসিং কার্যক্রম সম্পাদন করা বাঞ্ছনীয়। এটি প্রি-প্রসেসিং কাজগুলিতে আমাদের যে সময় ব্যয় করতে হবে তা হ্রাস করে বা সংরক্ষণ করে। এছাড়াও, একজন ডেটা বিশ্লেষক বা ডেটা সায়েন্টিস্ট হিসাবে, আপনি প্রায়শই নিজেকে অসংখ্য CSV ফাইল দ্বারা ওভারলোড করতে পারেন যা আপনার বিশ্লেষণ বা উপলব্ধ ডেটা পরীক্ষা শুরু করার আগে অবশ্যই মার্জ করতে হবে। অন্যদিকে, এটা সবসময় সম্ভব নয় যে সমস্ত ফাইল একক বা একই ডেটা উৎস থেকে প্রাপ্ত হয় এবং একই কলাম/ভেরিয়েবলের নাম এবং ডেটা স্ট্রাকচার থাকে। এই পোস্টটি আপনাকে দুই বা ততোধিক CSV ফাইলকে একই বা ভিন্ন কলামের কাঠামোর সাথে একত্রিত করতে শেখাবে।
কেন CSV ফাইল একত্রিত?
একটি ডেটা সেট একটি নির্দিষ্ট বিষয়ের সাথে সম্পর্কিত মান বা সংখ্যার সংগ্রহ বা গোষ্ঠী হতে পারে। উদাহরণস্বরূপ, একটি নির্দিষ্ট শ্রেণিতে প্রতিটি শিক্ষার্থীর পরীক্ষার ফলাফল একটি ডেটাসেটের উদাহরণ। বড় ডেটাসেটগুলির আকারের কারণে, সেগুলি প্রায়শই বিভিন্ন বিভাগের জন্য পৃথক CSV ফাইলগুলিতে সংরক্ষণ করা হয়। উদাহরণস্বরূপ, যদি আমাদের একটি নির্দিষ্ট রোগের জন্য রোগীর পরীক্ষা করার প্রয়োজন হয়, তাহলে আমাদের অবশ্যই তাদের লিঙ্গ, চিকিৎসা রেকর্ড, বয়স, রোগের তীব্রতা ইত্যাদি সহ প্রতিটি উপাদান বিবেচনা করতে হবে। ফলস্বরূপ, বিভিন্ন ভবিষ্যদ্বাণী-প্রভাব পরীক্ষা করার জন্য CSV ডেটা একত্রিত করা প্রয়োজন। দিক এছাড়াও, গণনা বা প্রিপ্রসেসিং কাজগুলি সম্পাদন করার সময় একাধিক ডেটাসেটের পরিবর্তে একটি একক ডেটাসেট কাজ করা এবং পরিচালনা করা ভাল। এটি মেমরি এবং অন্যান্য কম্পিউটেশনাল সম্পদ সংরক্ষণ করে
কিভাবে পাইথনে CSV ফাইল একত্রিত করবেন?
পাইথনে দুই বা ততোধিক CSV ফাইল একত্রিত করার একাধিক উপায় ও পদ্ধতি রয়েছে। নীচের বিভাগে, আমরা CSV ফাইলগুলিকে পান্ডাস ডেটাফ্রেমে একত্রিত করার জন্য append(), concat(), এবং merge() ফাংশন ইত্যাদি ব্যবহার করব তারপর ডেটাফ্রেমগুলি একটি একক CSV ফাইলে রূপান্তরিত হবে। আমরা শিখাবো কিভাবে একই বা পরিবর্তনশীল কলাম কাঠামোর সাথে একাধিক CSV ফাইল একত্রিত করা যায়।
পদ্ধতি # 1: অনুরূপ কাঠামো বা কলামের সাথে CSVs একত্রিত করা
আমাদের বর্তমান কাজের ডিরেক্টরিতে দুটি CSV ফাইল রয়েছে, 'test1' এবং 'test2'৷
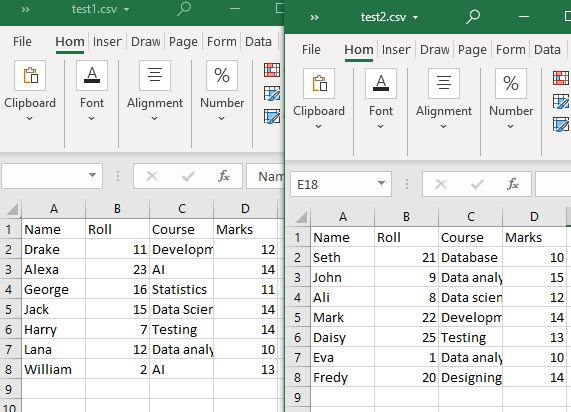
উদাহরণ # 1: append() ফাংশন ব্যবহার করে
উভয় CSV ফাইল একই কাঠামোর। glob() ফাংশন এই পদ্ধতিতে ব্যবহার করা হবে শুধুমাত্র ওয়ার্কিং ডাইরেক্টরিতে CSV ফাইলের তালিকা করতে। তারপরে আমরা আমাদের CSV ফাইলগুলি পড়তে (একটি সাধারণ টেবিল কাঠামো সহ) 'pandas.DataFrame.append()' ব্যবহার করব।

আউটপুট:
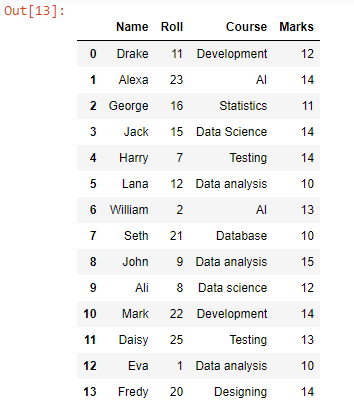
অ্যাপেন্ড ফাংশন ব্যবহার করে, আমরা test2.csv থেকে test1.csv-এর ডেটা সারিগুলির অধীনে প্রতিটি ডেটা সারি যুক্ত বা যোগ করেছি, কারণ এটি দেখা যায় যে ফাইলের সমস্ত ডেটা সারি একত্রিত হয়েছে। এই ডেটাফ্রেমটিকে CSV তে রূপান্তর করতে, আমরা to_csv() ফাংশনটি ব্যবহার করতে পারি।

এটি আমাদের ওয়ার্কিং ডিরেক্টরীতে 'test1' এবং 'test2'-এর CSV ফাইলগুলির একটি সম্মিলিত CSV ফাইল তৈরি করবে, যেমন, merged.csv।
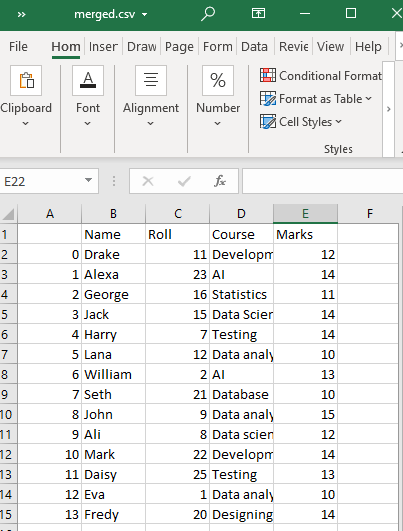
উদাহরণ # 2: concat() ফাংশন ব্যবহার করা
আমরা প্রথমে পান্ডাস মডিউল আমদানি করব। মানচিত্র পদ্ধতি pd.read_csv() ব্যবহার করে আমাদের পাস করা প্রতিটি CSV ফাইল পড়বে। এই ম্যাপ করা ফাইলগুলি (CSV ফাইলগুলি) তারপর ডিফল্টভাবে pd.concat() ফাংশন ব্যবহার করে সারি অক্ষ বরাবর মিলিত হবে। আমরা যদি CSV ফাইলগুলিকে অনুভূমিকভাবে একত্রিত করতে চাই, তাহলে আমরা axis=1 পাস করতে পারি। উপেক্ষা সূচকটি নির্দিষ্ট করা = True সম্মিলিত ডেটাফ্রেমের জন্য অবিচ্ছিন্ন সূচক মান তৈরি করে।

pd.read_csv() concat() ফাংশনের ভিতরে পাস করা হয় CSV ফাইলগুলিকে পান্ডাস ডাটাফ্রেমে পড়ার জন্য।
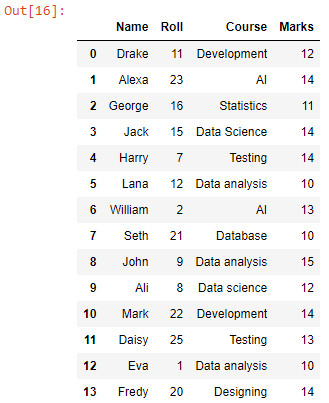
আমরা ওয়ার্কিং ডিরেক্টরিতে সমস্ত CSV ফাইলের সম্মিলিত ডেটা সহ একটি ডেটাফ্রেম পেয়েছি। এখন, এটিকে একটি CSV ফাইলে রূপান্তর করা যাক।
আমাদের সম্মিলিত CSV বর্তমান ডিরেক্টরিতে তৈরি করা হয়েছে।
পদ্ধতি # 2: বিভিন্ন স্ট্রাকচার বা কলামের সাথে CSV এর সমন্বয়
আমরা প্রথম পদ্ধতিতে একই কলাম এবং কাঠামোর সাথে CSV ফাইলগুলিকে একত্রিত করার বিষয়ে আলোচনা করেছি। এই পদ্ধতিতে, আমরা বিভিন্ন কলাম এবং কাঠামোর সাথে CSV ফাইলগুলিকে একত্রিত করব।
উদাহরণ # 1: মার্জ() ফাংশন ব্যবহার করা
পান্ডাস মডিউলের “pandas.merge()” ফাংশন দুটি CSV ফাইলকে একত্রিত করতে পারে। মার্জ করা বলতে বোঝায় শেয়ার করা কলাম বা বৈশিষ্ট্যের উপর ভিত্তি করে একটি একক ডেটাসেটে দুটি ডেটাসেটকে একত্রিত করা।
আমরা যোগদানের চারটি ভিন্ন উপায়ে ডেটাফ্রেমগুলিকে একত্রিত করতে পারি:
- ভিতরের
- ঠিক
- বাম
- বাইরের
এই ধরনের মার্জ করার জন্য, আমরা দুটি CSV ফাইল ব্যবহার করব।
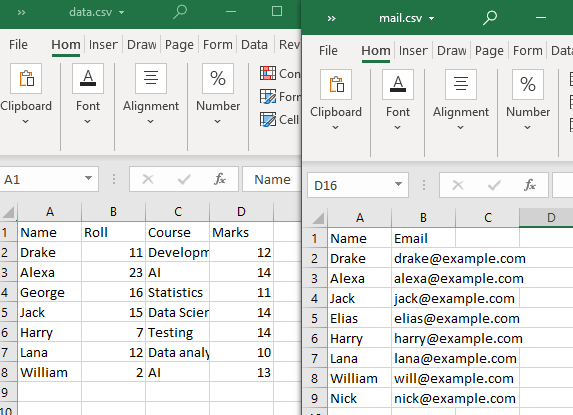
মনে রাখবেন যে উভয় CSV ফাইল দ্বারা কমপক্ষে একটি বৈশিষ্ট্য বা কলাম শেয়ার করা আবশ্যক। যেমন পর্যবেক্ষণ করা হয়েছে, কলাম 'নাম' এবং এর কিছু বৈশিষ্ট্য উভয় CSV ফাইল দ্বারা ভাগ করা হয়েছে৷
অভ্যন্তরীণ যোগদান ব্যবহার করে মার্জ করুন
মার্জ() ফাংশনে প্যারামিটার কীভাবে='inner' নির্দিষ্ট করা হলে তা নির্দিষ্ট কলাম অনুসারে দুটি ডেটাফ্রেমকে একত্রিত করবে এবং তারপরে একটি নতুন ডেটাফ্রেম প্রদান করবে যেটিতে শুধুমাত্র দুটি মূল ডেটাফ্রেমে অভিন্ন/একই মান সহ সারি রয়েছে।
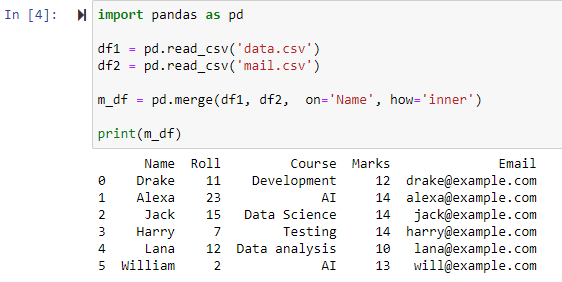
দেখা যায় যে ফাংশনটি উভয় CSV ফাইলকে একত্রিত করেছে এবং কলাম 'Name'-এর সাধারণ বৈশিষ্ট্যের উপর ভিত্তি করে সারিগুলি ফিরিয়ে দিয়েছে।
ডান বাইরের যোগদান ব্যবহার করে মার্জ
যখন প্যারামিটার how='right' নির্দিষ্ট করা হয়, তখন উভয় ডেটাফ্রেম আমরা 'চালু' প্যারামিটারের জন্য নির্দিষ্ট করা কলামের উপর ভিত্তি করে একত্রিত হবে। এবং ডান ডেটাফ্রেমের সমস্ত সারি সমন্বিত একটি নতুন ডেটাফ্রেম, যার জন্য বাম ডেটাফ্রেমে কোনও মান নেই এমন যে কোনও সারি সহ, বাম ডেটাফ্রেমের কলামের মানটি NAN এ সেট করে ফেরত দেওয়া হবে।
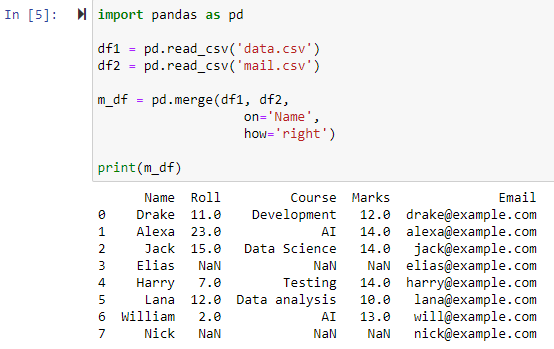
বাম বাইরের যোগদান ব্যবহার করে মার্জ করুন
যখন প্যারামিটারটিকে 'বাম' হিসাবে নির্দিষ্ট করা হয়, তখন 'চালু' প্যারামিটার ব্যবহার করে নির্দিষ্ট কলামের উপর ভিত্তি করে দুটি ডেটাফ্রেমকে একত্রিত করা হবে, একটি নতুন ডেটাফ্রেম ফেরত দেবে যাতে বাম ডেটাফ্রেমের সমস্ত সারি রয়েছে এবং সেইসাথে NAN আছে এমন যেকোনো সারি রয়েছে বা সঠিক ডেটাফ্রেমে নাল মান এবং সঠিক ডেটাফ্রেম কলামের মান NAN এ সেট করে।
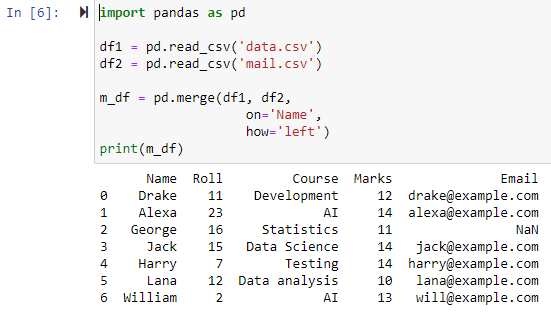
সম্পূর্ণ বাইরের যোগদান ব্যবহার করে মার্জ করুন
যখন কিভাবে='outer' নির্দিষ্ট করা হয়, তখন 'চালু' প্যারামিটারের জন্য নির্দিষ্ট করা কলামের উপর নির্ভর করে দুটি ডেটাফ্রেমকে একত্রিত করা হবে, একটি নতুন ডেটাফ্রেম ফেরত দেওয়া হবে যাতে df1 এবং df2 ডেটাফ্রেম উভয়ের সারি রয়েছে এবং যেকোনো সারির মান হিসেবে NAN সেট করা হবে। যার জন্য ডেটা ফ্রেমের একটিতে ডেটা অনুপস্থিত।
উদাহরণ # 2: ওয়ার্কিং ডিরেক্টরিতে সমস্ত CSV ফাইল একত্রিত করা
এই পদ্ধতিতে, আমরা সমস্ত .csv ফাইলগুলিকে একটি পান্ডাস ডেটাফ্রেমে একত্রিত করতে গ্লোব মডিউল ব্যবহার করব। সব লাইব্রেরি আগে আমদানি করতে হতো। এর পরে, আমরা প্রতিটি CSV ফাইলের জন্য একটি পথ সেট করব যা আমরা একত্রিত করতে চাই। ফাইল পাথ হল নিচের উদাহরণে os.path.join() ফাংশনের প্রথম আর্গুমেন্ট, এবং দ্বিতীয় আর্গুমেন্ট হল পাথ উপাদান বা .csv ফাইল যুক্ত করা। এখানে, '*.csv' অভিব্যক্তিটি .csv ফাইল এক্সটেনশনের সাথে শেষ হওয়া ওয়ার্কিং ডিরেক্টরিতে প্রতিটি ফাইল খুঁজে বের করবে এবং ফেরত দেবে। glob.glob(ফাইল যোগ হয়েছে) ফাংশন ইনপুট হিসাবে মার্জ করা ফাইলের নামের একটি তালিকা গ্রহণ করে এবং সমস্ত মার্জড/একত্রিত ফাইলের একটি তালিকা আউটপুট করে।
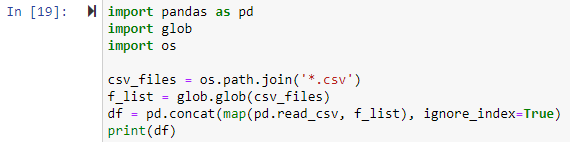
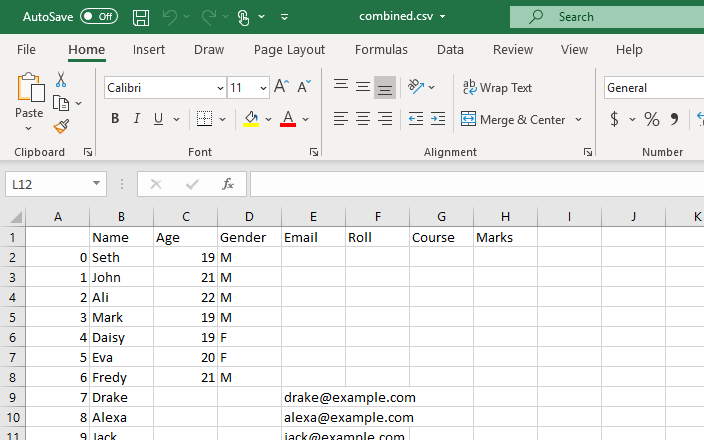
এই স্ক্রিপ্টটি আমাদের কাজের ডিরেক্টরির সমস্ত CSV ফাইলের সম্মিলিত ডেটা সহ একটি ডেটাফ্রেম ফিরিয়ে দেবে।
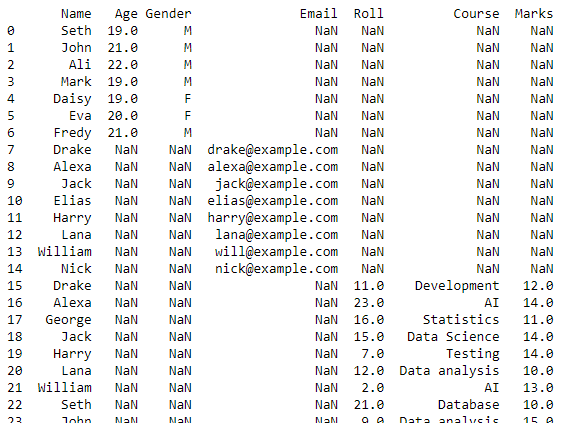
এই ডেটাফ্রেমটি একটি CSV ফাইলে রূপান্তরিত হবে এবং to_csv() ফাংশনটি এই রূপান্তরের জন্য ব্যবহার করা হবে। এই নতুন CSV ফাইলটি বর্তমান কার্যকারী ডিরেক্টরিতে সংরক্ষিত সমস্ত CSV ফাইল থেকে তৈরি করা সম্মিলিত CSV ফাইল হবে৷
উপসংহার
এই পোস্টে, আমরা আলোচনা করেছি কেন আমাদের CSV ফাইল একত্রিত করতে হবে। আমরা আলোচনা করেছি কিভাবে পাইথনে দুই বা ততোধিক CSV ফাইল একত্রিত করা যায়। আমরা এই টিউটোরিয়ালটিকে দুটি ভাগে ভাগ করেছি। প্রথম বিভাগে, আমরা ব্যাখ্যা করেছি কিভাবে একই কাঠামো বা কলামের নামের CSV ফাইলগুলিকে একত্রিত করতে append() এবং concat() ফাংশন ব্যবহার করতে হয়। দ্বিতীয় বিভাগে, আমরা বিভিন্ন কলাম এবং কাঠামোর CSV ফাইলগুলিকে একত্রিত করার জন্য মার্জ() পদ্ধতি, os.path.join(), এবং গ্লোব পদ্ধতি ব্যবহার করেছি।