'পান্ডাস' হল পাইথন পরিবেশের জন্য একটি উচ্চ-কার্যক্ষমতার টুল। এটি ডেটা বিশ্লেষণের জন্য একটি 'ওপেন' সোর্স কোড। পান্ডা যোগদান এবং পান্ডা মার্জ পদ্ধতি দুটি ডেটাফ্রেমকে একসাথে একটি একক ডেটাফ্রেমে যুক্ত করার জন্য ব্যবহার করা হয়। পান্ডা উভয় পদ্ধতিতে, পার্থক্য হল যে পান্ডা 'যোগদান' ফাংশন একটি সূচক ব্যবহার করে ডেটাফ্রেমে যোগদান করে। যদিও পান্ডা 'মার্জ' ফাংশন ইনডেক্স এবং কলাম পদ্ধতি ব্যবহার করে ডেটাফ্রেমে যোগ দেয় যেখানে আমরা নিজেরাই পছন্দসই কলাম নির্বাচন করতে পারি। পান্ডাদের একত্রীকরণ পদ্ধতি বেশিরভাগ পান্ডাদের যোগদান পদ্ধতির তুলনায় ব্যবহৃত হয়। বাস্তবায়নের জন্য আমরা যে সফ্টওয়্যারটি ব্যবহার করব তা হল 'স্পাইডার' সফ্টওয়্যার, যা পাইথন পরিবেশে রয়েছে যা আমাদের পান্ডা জয়েন মেথড() এবং পান্ডাস মার্জ() মেথড ফাংশনের কোড বাস্তবায়নের সুবিধা প্রদান করবে।
পান্ডা জয়েন() পদ্ধতির সিনট্যাক্স
'df1. যোগদান ( df2 ) 'উপরের সিনট্যাক্সে 'df' হল 'ডেটাফ্রেম' এর সংক্ষিপ্ত রূপ। সিনট্যাক্সে 'ডট জয়েন' ফাংশন সহ দুটি ডেটাফ্রেম রয়েছে, যা পদ্ধতিটি কল করার জন্য। এটি দুটি ডেটাফ্রেমে যোগদানের পান্ডাস পদ্ধতি। এটি একটি একক ডেটাফ্রেমগুলিকে একত্রিত করতে সূচক ব্যবহার করে কাজ করে।
পান্ডাস মার্জ() পদ্ধতির সিনট্যাক্স
'df1. একত্রিত করা ( df2 , চালু = 'কলাম_নাম' ) 'পান্ডাস মার্জ পদ্ধতির সিনট্যাক্সে 'df1' এবং 'df2' হিসাবে দুটি ডেটাফ্রেম রয়েছে। 'ডট মার্জ' ফাংশনটি উল্টানো কলামের উপস্থিতি সহ উভয় ডেটাফ্রেমে যোগদানের পদ্ধতিকে কল করছে।
পান্ডা মার্জ এবং পান্ডা যোগদানের পদ্ধতিগুলি ব্যবহার করার জন্য আমরা দুটি ডেটাফ্রেমকে একত্রিত করার নিম্নলিখিত উপায়গুলি কভার করব:
- পান্ডা জয়েন পদ্ধতি ওভারল্যাপিং।
- পান্ডা একটি সূচক রিসেট ব্যবহার করে পদ্ধতিতে যোগদান করে।
- পান্ডাস মার্জ পদ্ধতি (কলাম 'বাম এবং ডান')।
- পান্ডা মার্জ পদ্ধতি সুস্পষ্ট।
পান্ডাস মার্জ এবং পান্ডাস জয়েন পদ্ধতি বাস্তবায়নের জন্য ডেটাফ্রেম তৈরি করা
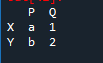
প্রথমত, আমাদের একটি ডেটা ফ্রেম তৈরি করতে হবে। এর জন্য, আমরা 'স্পাইডার' টুল ব্যবহার করব। এটি খোলার পরে, কোড লেখা শুরু করুন। পান্ডা লাইব্রেরি অ্যাসোসিয়েশনের জন্য 'pd' হিসাবে পান্ডাগুলি আমদানি করুন৷ আমাদের কাছে 'x', 'y', 'p', এবং 'q অনুরূপভাবে এবং 'a' মান সহ '1' এবং 'b' মান সহ '2' হিসাবে নির্ধারিত মান রয়েছে।

আউটপুট একটি 'df' নির্ধারিত মান দিয়ে তৈরি। আমরা এটিকে ডেটা হিসাবে বড় করতে পারি।
আরেকটি ডেটাফ্রেম তৈরি করা হচ্ছে
আমাদের আরেকটি ডেটাফ্রেম তৈরি করতে হবে, পান্ডাদের যোগদানের পদ্ধতি এবং পান্ডা একত্রিত হওয়ার পদ্ধতিগুলি স্পষ্টভাবে বোঝার জন্য। এখানে, আমরা উপরের 'df' এর মতোই 'df' তৈরি করেছি, কেবলমাত্র ভ্যারিয়েবলের মানগুলি আলাদা। আমাদের আছে “h”, “j”, “s” এবং “d”, যেখানে “b” মানের সাথে “8” এবং “Y” মান “3” এর সাথে বরাদ্দ করুন।

আউটপুট একটি সাধারণ 'df' তৈরি দেখায়।

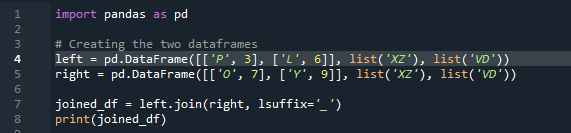
উদাহরণ # 01: পান্ডা যোগদানের পদ্ধতি (ওভারল্যাপিং)
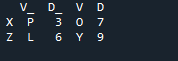
এখন, আমরা দেখব কিভাবে পান্ডা জয়েন মেথড দিয়ে দুটি ডেটাফ্রেম যোগ করা যায়। এই পদ্ধতির জন্য, আমরা ডেটাফ্রেম থেকে আপনার পছন্দের কলামটি বেছে নিতে পারি যেটিতে আমরা কাজ করতে চাই। আমরা 'df' থেকে ওভারল্যাপিং কলাম 'বাম' সহ উদাহরণ নিয়েছি, তাই আমরা ডেটার ওভারল্যাপিং কাটিয়ে উঠতে 'প্রত্যয়' দিয়ে এটি ঠিক করতে পারি। এখানে, ব্যবহৃত ভেরিয়েবলগুলি হল “x”, “z”, “v”, “d”। “p”, “o”, “l”, এবং “y” মান সহ “3”, “6”, “7”, এবং “9” হিসাবে বরাদ্দ করা হয়েছে। '.join' পদ্ধতিটিকে কল করে, ডান 'df' প্রত্যয়ের সাথে বাম যোগে সারিবদ্ধ সেট সহ। ” কোডে 'প্রত্যয়' ব্যবহার করা হয়েছে কারণ ডেটাফ্রেমে, দুটি কলাম রয়েছে যার নাম 'কী' এবং এটি ডেটাকে ওভারল্যাপ করবে না।
আউটপুট পান্ডা জয়েন পদ্ধতি ব্যবহার করে দুটি 'df' যোগ করার পদ্ধতির সাথে কোনো ওভারল্যাপড ডেটা প্রদর্শন করে না।
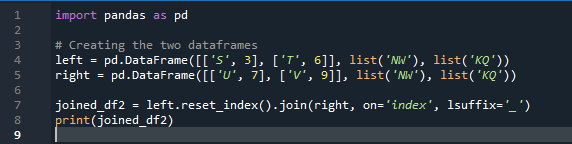
উদাহরণ # 02: একটি সূচক রিসেট ব্যবহার করে পান্ডাস যোগদানের পদ্ধতি
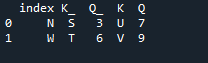
এই উদাহরণে, আমরা আলাদাভাবে যোগ করার পদ্ধতিতে 'কী' হিসাবে ব্যবহার করার জন্য প্যারামিটার 'চালু' সহ কলামটি নির্দিষ্ট করব যা দুটি ডেটাফ্রেমে যোগদান করতে সহায়তা করে। এই পরামিতি দিয়ে সম্মিলিত জিনিসটি করা হয়। এছাড়াও, দুটি 'df' এর একটির সূচী তাদের যোগদানের জন্য অনুরূপ হওয়া উচিত। একই ধরনের ডেটা বা একই উদ্দেশ্যে ব্যবহৃত ডেটা প্রক্রিয়াকরণের জন্য একসাথে থাকতে পারে। এটি ডান থেকে ব্যবহার করে সূচকটি এখনও ব্যবহার করবে। ভেরিয়েবল হল “s”, “t”, “u”, “v”, “n”, ‘w”, “k”, এবং “q”। নির্ধারিত মানগুলি হল “3”, “6”, “7” এবং “9”। 'রিসেট ডট ইনডেক্স' হল 'df' এর সূচক রিসেট করার জন্য পান্ডাদের একটি পদ্ধতি। রিসেট ইনডেক্স আপনার ডেটাফ্রেম তালিকার সমস্ত পূর্ণসংখ্যা 0 থেকে সেট করে যতক্ষণ পর্যন্ত না ডেটাফ্রেম ডেটা দীর্ঘ হয়।
এখানে সূচী 'কী' পান্ডা যোগ করার পদ্ধতির সাথে আউটপুট প্রদর্শিত হচ্ছে।
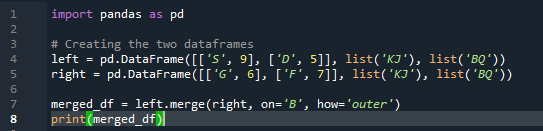
উদাহরণ # 03: পান্ডাস মার্জ পদ্ধতি (কলাম 'বাম এবং ডান')
একত্রীকরণ পদ্ধতিটি পান্ডা যোগদানের পদ্ধতির মতো একই রকম কাজ করে। উভয় পদ্ধতিই একটি অনুরূপ ডেটাফ্রেমে ডেটা একত্রিত করার জন্য। মার্জ পদ্ধতিটি আরও বহুমুখী যার জন্য কী নির্দিষ্ট করা প্রয়োজন। আপনার ডেটাফ্রেমের কাজের উপর নির্ভর করে আমরা এটিকে বাম এবং ডান কলামে নির্দিষ্ট করতে পারি। কোডের ভেরিয়েবলগুলো হল “s”, “d”, “g”, “f”, “k”, “j”, “b” এবং “q”। নির্ধারিত মানগুলি হল “9”, “5”, “6” এবং “7”। পান্ডা মার্জ মেথড ফাংশনের প্যারামিটার 'কিভাবে' ব্যবহার করে 'df' উভয় ক্ষেত্রেই বাইরের 'যোগদান' বাস্তবায়ন করা হয়।
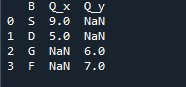
আমরা যে আউটপুট দেখি তা দুটি ডেটাফ্রেমের একত্রিত ডেটা দেখায়। 'NaN' প্রতিনিধিত্ব করে 'কোনও সংখ্যা নয়' যার মানে যেখানে ডেটাতে কোনো নম্বর বরাদ্দ নেই সেখানে 'NaN' দেখায়।
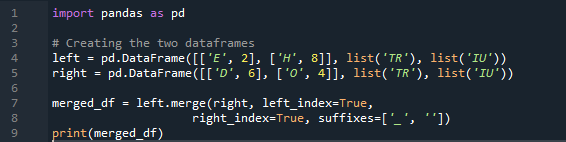
উদাহরণ # 04: মার্জ পদ্ধতি স্পষ্টভাবে
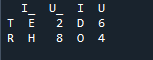
এখানে, এই উদাহরণে, মার্জ পদ্ধতি হল সূচকের ধ্বংস এবং সূচকের মান ডেটাফ্রেমে ধরে নেওয়া হয় না। আমরা এই পদ্ধতিতে কাজ করার জন্য প্রয়োজনীয় কাজ অনুযায়ী কাজ করব, যেখানে সুনির্দিষ্ট স্পষ্টভাবে অনুসরণ করতে হবে। এটি প্যারামিটারের সাথে একটি বাম সূচক বা ডান সূচকের উপর ভিত্তি করে ডেটা মার্জ করবে। এই ডেটাফ্রেমের ভেরিয়েবলগুলি হল “t”, “r”, “I”, “u”, “h”, “o”, “e”, এবং “e”। নির্ধারিত মানগুলি হল “2”, “4”, “6” এবং “4”। প্রয়োজন অনুসারে কলাম নির্বাচনের সাথে পান্ডা মার্জ পদ্ধতির উপরের উদাহরণটি দুটি ডেটাফ্রেমে যোগদানের সবচেয়ে উপস্থাপনযোগ্য এবং মূল্যবান পদ্ধতি। ডেটাসেটে মার্জ কী অনন্য হওয়ার বিষয়ে কোডের লাইনের শেষে পরীক্ষা করা হচ্ছে।
নীচের আউটপুটে সূচীটি সূচক ছাড়া দেখানো হয় না তবে ফাংশনটি ডান এবং বাম সূচকের উপর ভিত্তি করে সঞ্চালিত হয়।
উপসংহার
মার্জ() এবং join() পদ্ধতি দুটিই খুব সুবিধাজনক এবং কার্যকরী পদ্ধতি। এই দুটি ফাংশন একই ডেটাফ্রেমে দুটি পৃথক ডেটাফ্রেমে যোগদানের জন্য ব্যবহৃত হয় তবে ক্ষেত্রের উপর নির্ভর করে ভিন্ন ভিন্ন ব্যবহার রয়েছে। এই নিবন্ধে, আমরা পান্ডা যোগদান এবং মার্জ পদ্ধতির মধ্যে মূল পার্থক্য শিখেছি। উদাহরণগুলি করার পরে এবং পান্ডা যোগদান পদ্ধতিটি বোঝার পরে, আমরা এই জ্ঞানের সাথে এটি শেষ করব যে, আমরা যদি আরও নমনীয় এবং ডাটাবেস শৈলীতে যোগদান করতে চাই তবে পান্ডা মার্জ পদ্ধতিতে যাওয়াই বাঞ্ছনীয়। অন্যদিকে, যদি আমরা ডাটাফ্রেমকে সূচকের সাথে বিস্তৃতভাবে একত্রিত করতে চাই, তাহলে আমরা পান্ডাস join() মেথড ফাংশনের সাথে যেতে পারি।