“পাইথনে, ডিকশনারি নামে একটি ডাটা স্ট্রাকচার ব্যবহার করা হয় মূল-মান জোড়া হিসাবে তথ্য সংরক্ষণ করতে। যখন কী বা কীগুলি পরিচিত হয় তখন অভিধান বস্তুগুলি ডেটা/মানগুলি বের করার জন্য অপ্টিমাইজ করা হয়। মনে রাখবেন যে অভিধানগুলি ডুপ্লিকেট কীগুলি অন্তর্ভুক্ত করতে পারে৷ সম্পর্কিত সূচক ব্যবহার করে দক্ষতার সাথে মানগুলি খুঁজে পেতে, আমরা একটি প্রাসঙ্গিক সূচক সহ একটি পান্ডাস সিরিজ বা ডেটাফ্রেমকে 'সূচক: মান' কী-মান জোড়া সহ একটি অভিধান অবজেক্টে রূপান্তর করতে পারি। এই কাজটি অর্জন করতে, 'to_dict()' পদ্ধতি ব্যবহার করা যেতে পারে। এই ফাংশনটি একটি অন্তর্নির্মিত ফাংশন যা পান্ডাস মডিউলের সিরিজ ক্লাসে পাওয়া যায়। প্রাচ্যের প্যারামিটারের নির্দিষ্ট মানের উপর নির্ভর করে pandas.to_dict() পদ্ধতি ব্যবহার করে একটি ডাটাফ্রেমকে পাইথন তালিকার মতো সিরিজের ডেটা অভিধানে রূপান্তরিত করা হয়।'
কিভাবে পান্ডাকে একটি পাইথন অভিধানে রূপান্তর করবেন?
পান্ডাকে একটি অভিধানে রূপান্তর করার একাধিক পদ্ধতি রয়েছে। যাইহোক, একটি পান্ডাস ডেটাফ্রেমকে পাইথন অভিধানে রূপান্তর করতে, আমরা পান্ডাসে to_dict() পদ্ধতি ব্যবহার করব। আমরা to_dict() ফাংশন ব্যবহার করে বিভিন্ন উপায়ে প্রত্যাবর্তিত অভিধানের কী-মান জোড়াকে নির্দেশ করতে পারি। ফাংশনের সিনট্যাক্স নিম্নরূপ:
বাক্য গঠন
pandas.to_dict ( পূর্ব = 'ডিক্ট', মধ্যে = )
পরামিতি
প্রাচ্য কোন ডেটাটাইপ কলামগুলিকে (সিরিজ-এ) রূপান্তর করতে হবে তা স্ট্রিং মান (“ডিক্ট”, “লিস্ট”, “রেকর্ডস”, “ইনডেক্স”, “সিরিজ”, “বিভক্ত”) দ্বারা নির্দিষ্ট করা হয়। উদাহরণস্বরূপ, 'তালিকা' কীওয়ার্ডটি আউটপুট হিসাবে 'কলামের নাম' এবং 'তালিকা' (রূপান্তরিত সিরিজ) কী সহ তালিকা বস্তুর একটি পাইথন অভিধান দেবে।
মধ্যে: ক্লাস, একটি উদাহরণ বা প্রকৃত ক্লাস হিসাবে পাস করা যেতে পারে। উদাহরণস্বরূপ, একটি ডিফল্ট ডিক্টের ক্ষেত্রে একটি ক্লাস উদাহরণ পাস করা যেতে পারে। প্যারামিটারের ডিফল্ট মান হল dict।
রিটার্ন টাইপ: একটি ডেটাফ্রেম বা সিরিজ থেকে রূপান্তরিত অভিধান।
উদাহরণ # 01: পান্ডাস ডেটাফ্রেমকে একটি অভিধানে রূপান্তর করা
pd.DataFrame() ফাংশনে তালিকার টুপল ব্যবহার করে, আমরা কিছু কলাম এবং সারি সহ একটি মৌলিক ডেটাফ্রেম তৈরি করব যাতে আমরা পরে এটিকে একটি পাইথন অভিধানে রূপান্তর করতে পারি।
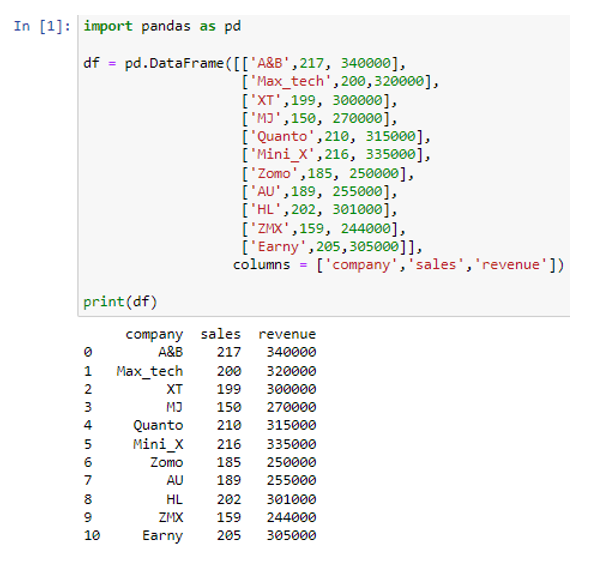
আমরা pd.DataFrame() ফাংশনের ভিতরে তালিকা পাস করে আমাদের ডেটাফ্রেম তৈরি করেছি। উপরের ডেটাফ্রেমে, আমাদের তিনটি কলাম রয়েছে 'কোম্পানী', 'বিক্রয়', এবং 'রাজস্ব'। কলাম কোম্পানিতে, আমরা এলোমেলো কোম্পানির নাম সংরক্ষণ করেছি (“A&B”, “Max_tech”, “XT”, “MJ”, “Quanto”, “Mini_X”, “Zomo”, “AU”, “HL” , “ZMX”, “আর্নি”), কলাম “বিক্রয়” প্রতিটি কোম্পানির বিক্রয়কে প্রতিনিধিত্ব করছে (“217”, “200”, “199”, “150”, “210”, “216”, “185” ”, “189”, “202”, “159”, “205”), এবং কলাম “রাজস্ব” সংশ্লিষ্ট বিক্রয়ের বিপরীতে প্রতিটি কোম্পানির রাজস্ব প্রতিনিধিত্বকারী মান সংরক্ষণ করছে (340000 320000 300000 270000 315000 50 50 50 50 50 50 2000 3000 3000 3000 320000 305000)। এখন আমরা আমাদের ডেটাফ্রেম 'df' কে একটি পাইথন অভিধানে রূপান্তর করব।
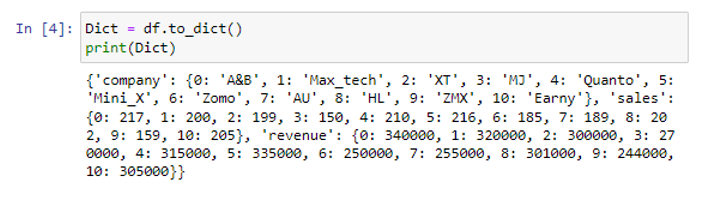
df ডেটাফ্রেমে to_dict() পদ্ধতি প্রয়োগ করে, আমরা একটি পান্ডাস ডেটাফ্রেমকে একটি অভিধানে রূপান্তর করেছি।
উদাহরণ # 02: একটি CSV ফাইল থেকে তৈরি পান্ডাস ডেটাফ্রেমকে একটি অভিধানে রূপান্তর করা
উদাহরণ # 1, আমরা তালিকার ভিতরে tuples ব্যবহার করে একটি ডেটাফ্রেম তৈরি করেছি। এখন আমরা একটি CSV ফাইলের সাহায্যে একটি ডেটাফ্রেম তৈরি করব, এবং তারপর আমরা to_dict() ফাংশন ব্যবহার করে এটিকে একটি অভিধানে রূপান্তর করব।
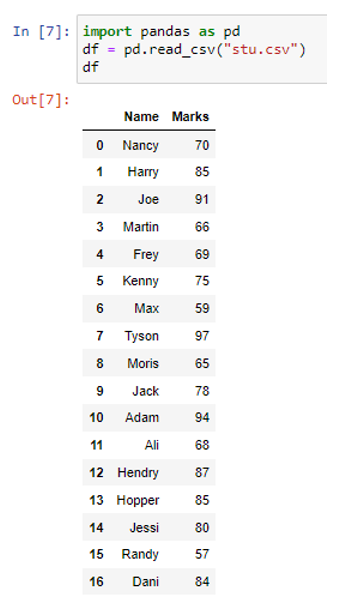
একটি ডেটাফ্রেম হিসাবে একটি ফাইল পড়ার জন্য, আমরা pd.read_csv() ফাংশন ব্যবহার করেছি। উপরের ডেটাফ্রেমে, আমাদের দুটি কলাম (নাম এবং চিহ্ন) এবং সতেরোটি সারি (0 থেকে 16 পর্যন্ত) রয়েছে। এখন আমরা to_dict() পদ্ধতি ব্যবহার করব।
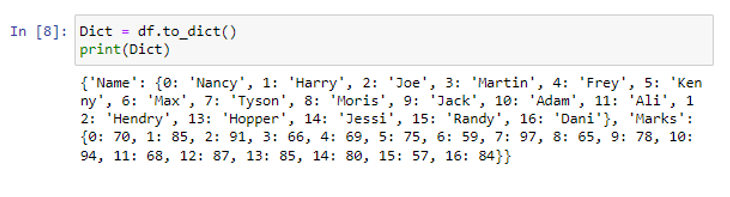
ফাংশনটি আমাদের ডেটাফ্রেম 'df' কে একটি পাইথন অভিধানে রূপান্তরিত করেছে।
উদাহরণ # 03: পান্ডাস ডেটাফ্রেমকে মানের তালিকা সম্বলিত অভিধানে রূপান্তর করুন
আগের উদাহরণগুলিতে, আমরা পান্ডাগুলিকে একাধিক অভিধান ধারণকারী একটি পাইথন অভিধানে রূপান্তর করেছি। একটি ডেটাফ্রেমকে একটি অভিধান অবজেক্টে রূপান্তর করার সময়, কলাম লেবেলগুলি অভিধানের কী হিসাবে পরিবেশন করা উচিত, এবং প্রতিটি কী-এর জন্য একটি মান তালিকা হিসাবে কলামের সমস্ত ডেটা বা মান ফলাফল অভিধানে যোগ করা উচিত।
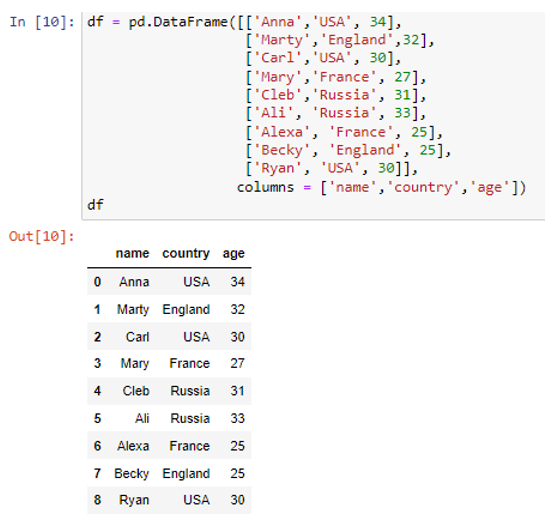
আমরা তিনটি কলাম 'নাম', 'দেশ' এবং 'বয়স' সহ ডেটাফ্রেম তৈরি করেছি। 'নাম' কলামে, আমরা ডেটা মানগুলি সংরক্ষণ করেছি ('আন্না', 'মার্টি', 'কার্ল', 'মেরি', 'ক্লেব', 'আলি', 'আলেক্সা', 'বেকি', 'রায়ান') . অন্যান্য কলামের দেশ এবং বয়স যেমন শক্তিশালী মান (“USA”, “England”, “USA”, “France”, “Russia”, “Russia”, “France”, “England”, “USA”) এবং ( 34, 32, 30, 27, 31, 33, 35, 25, 30) যথাক্রমে। আমরা to_dict() পদ্ধতির মধ্যে 'তালিকা' প্যারামিটার ব্যবহার করে তালিকা সমন্বিত একটি অভিধান তৈরি করব।
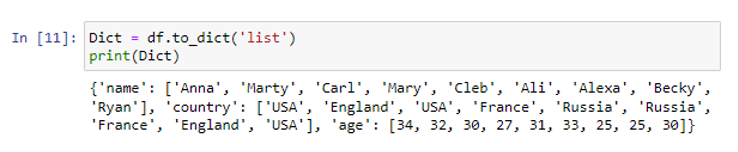
to_list() ফাংশনের ভিতরে একটি আর্গুমেন্ট হিসাবে তালিকা প্যারামিটার ব্যবহার করে, আমরা একাধিক তালিকা সম্বলিত একটি অভিধান তৈরি করেছি।
উদাহরণ # 03: পান্ডাস ডেটাফ্রেমকে মানগুলির সিরিজ সম্বলিত অভিধানে রূপান্তর করুন
যখন একটি ডেটাফ্রেমকে একটি অভিধানে রূপান্তরিত করার প্রয়োজন হয়, তখন কলামের নাম অভিধান কী হিসাবে কাজ করে এবং সারি সূচী এবং কলামের ডেটা অভিধানে সংশ্লিষ্ট কীগুলির জন্য একটি মান হিসাবে কাজ করে।
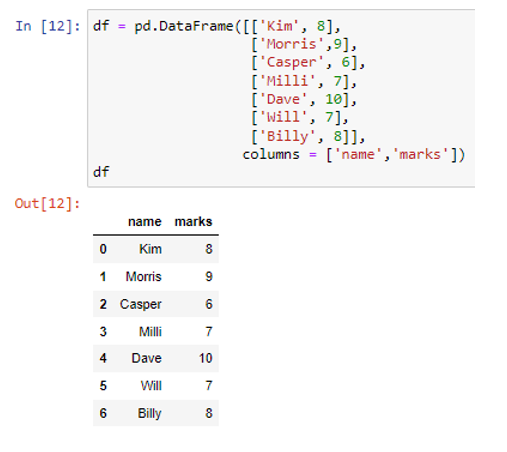
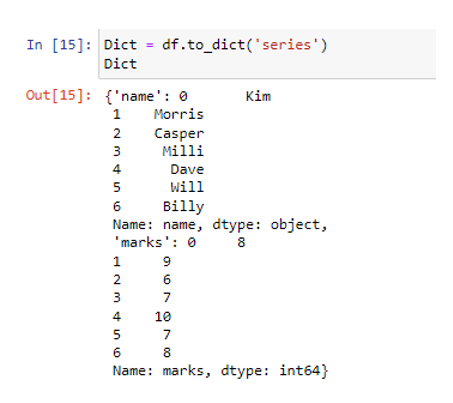
আমরা pd.DataFrame() পদ্ধতি ব্যবহার করে প্রয়োজনীয় ডেটাফ্রেম তৈরি করেছি। সম্প্রতি তৈরি করা ডেটাফ্রেমে, আমাদের দুটি কলাম রয়েছে। নামের কলামটি একটি স্ট্রিং (“কিম”, “মরিস”, “ক্যাসপার”, “মিলি”, “ডেভ”, “উইল”, “বিলি”) হিসাবে ডেটা মানগুলি সংরক্ষণ করে, যেখানে চিহ্নের কলামগুলি হিসাবে সাংখ্যিক ডেটা থাকে ( 8, 9, 6, 7, 10, 7, 8)। আমরা to_dict() ফাংশনের ভিতরে একটি স্ট্রিং হিসাবে প্যারামিটার 'সিরিজ' ব্যবহার করব।
উদাহরণ # 04: পান্ডাস ডেটাফ্রেমকে সূচক এবং শিরোনাম ছাড়াই অভিধানে রূপান্তর করুন
to_dict() ফাংশনের প্যারামিটার 'বিভক্ত' কলামের শিরোনাম ছাড়াই ডেটাফ্রেম থেকে ডেটা বের করতে বা যখন আমাদের ডেটা থেকে হেডার এবং সারি সূচক অপসারণ করতে হবে তখন ব্যবহার করা যেতে পারে। এই পরামিতি ব্যবহার করে কলাম লেবেল, সারি সূচক এবং প্রকৃত ডেটা তিনটি উপাদানে বিভক্ত করা হয়েছে। আসুন একটি ডেটাফ্রেম তৈরি করি, যাতে আমরা এটিকে অভিধানে রূপান্তর করার সময় এটিকে তিনটি অংশে বিভক্ত করতে পারি।
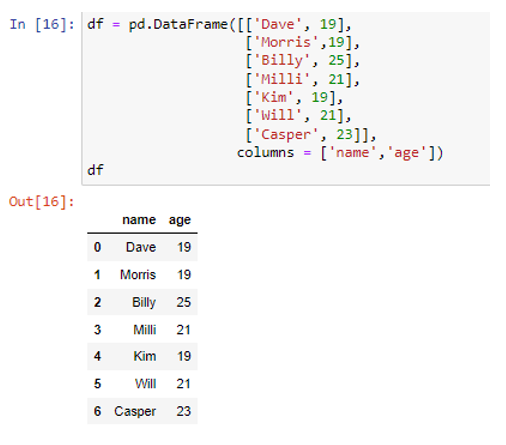
আমরা 'নাম' এবং 'বয়স' লেবেল সহ দুটি কলাম তৈরি করেছি যেখানে মান রয়েছে (“ডেভ”, “মরিস”, “বিলি”, “মিলি”, “কিম”, “উইল”, “ক্যাসপার”) এবং (19, 19) , 25, 21, 19, 21, 23) যথাক্রমে। আসুন সেগুলিকে পাইথন অভিধানে রূপান্তর করি।

কী 'ডেটা' ব্যবহার করে, আমরা কোনো সূচক বা শিরোনাম ছাড়াই ফলাফল অভিধান থেকে ডেটা পুনরুদ্ধার করতে পারি।

উদাহরণ # 05: পান্ডাস ডেটাফ্রেমকে সারি এবং সারি সূচক দ্বারা অভিধানে রূপান্তর করুন
প্যারামিটার 'রেকর্ড' to_dict() ফাংশনের ভিতরে ব্যবহার করা যেতে পারে প্রতিটি ডেটাফ্রেম সারির ডেটা একটি তালিকার ভিতরে একাধিক স্বতন্ত্র অভিধান অবজেক্টে সংরক্ষণ করতে বা যখন সারি-ভিত্তিক ডেটা প্রয়োজন হয়। অভিধান বস্তু সম্বলিত একটি তালিকা ফেরত দেওয়া হবে। প্রতিটি সারির মান হিসাবে একটি কলাম লেবেল কী এবং কলাম ডেটা সহ একটি অভিধান৷
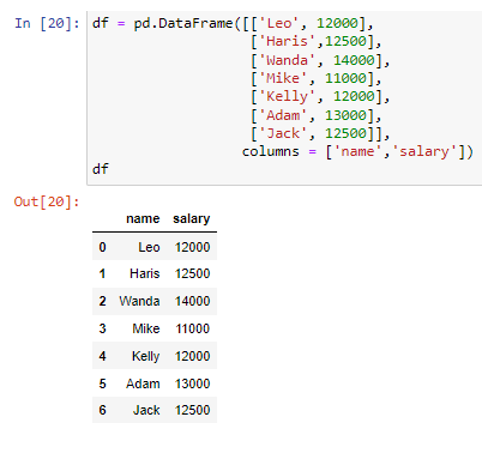
আমরা 'নাম' এবং 'বেতন' কলাম সহ একটি ডেটাফ্রেম তৈরি করেছি। 'নাম' কলামে ডেটা মান রয়েছে ('লিও', 'হারিস', 'ওয়ান্ডা', 'মাইক', 'কেলি', 'অ্যাডাম', 'জ্যাক'), এবং বেতন কলাম মানগুলি সংরক্ষণ করে (12000, 12500) , 14000, 11000, 12000, 13000, 12500)। এখন প্রতিটি সারির ডেটা সহ একাধিক পাইথন অভিধান সহ একটি তালিকা তৈরি করা যাক।

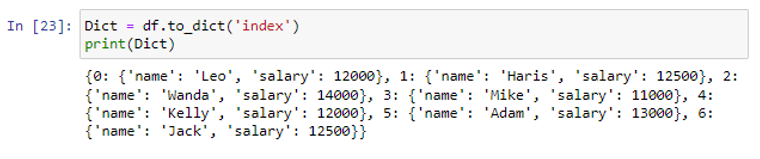
সূচক প্যারামিটারটি প্রতিটি সারির ডেটাকে ডেটাফ্রেম থেকে একটি অভিধানে রূপান্তর করতেও ব্যবহার করা যেতে পারে। অভিধান আইটেম ধারণকারী একটি তালিকা ফেরত দেওয়া হবে. প্রতিটি সারি একটি অভিধান তৈরি করে। যেখানে সারি ইনডেক্স হবে কী এবং মান হবে ডাটা এবং কলাম লেবেলের অভিধান।
উপসংহার
এই টিউটোরিয়ালে, আমরা আলোচনা করেছি কিভাবে আমরা ডাটাফ্রেম বা পান্ডাস অবজেক্টকে পাইথন অভিধানে রূপান্তর করতে পারি। আমরা এই ফাংশনের প্যারামিটার বোঝার জন্য to_dict() ফাংশনের সিনট্যাক্স দেখেছি এবং কিভাবে আপনি বিভিন্ন প্যারামিটার সহ ফাংশন নির্দিষ্ট করে ফাংশনের আউটপুট পরিবর্তন করতে পারেন। এই টিউটোরিয়ালের উদাহরণগুলিতে, আমরা to_dict() পদ্ধতি ব্যবহার করেছি, একটি অন্তর্নির্মিত পান্ডাস ফাংশন, পান্ডাস বস্তুগুলিকে পাইথন অভিধানে পরিবর্তন করতে।