এই টিউটোরিয়ালে, আমরা এসকিউএল-এ PARTITION BY ক্লজের কার্যকারিতা সম্পর্কে শিখব এবং আবিষ্কার করব কীভাবে আমরা আরও দানাদার উপসেটের জন্য ডেটা ভাগ করতে এটি ব্যবহার করতে পারি।
বাক্য গঠন:
চলুন শুরু করা যাক PARTITION BY clause-এর সিনট্যাক্স দিয়ে। সিনট্যাক্সটি আপনি যে প্রেক্ষাপটে এটি ব্যবহার করেন তার উপর নির্ভর করতে পারে তবে এখানে সাধারণ সিনট্যাক্স রয়েছে:
কলাম 1, কলাম 2, ... নির্বাচন করুন
ওভার (পার্টিশন_কলাম 1, পার্টিশন_কলাম 2, ...) দ্বারা বিভাজন
টেবিল_নাম থেকে
প্রদত্ত সিনট্যাক্স নিম্নলিখিত উপাদানগুলির প্রতিনিধিত্ব করে:
- column1, column2 - এটি সেই কলামগুলিকে বোঝায় যা আমরা ফলাফল সেটে অন্তর্ভুক্ত করতে চাই।
- কলাম দ্বারা বিভাজন - এই ধারাটি সংজ্ঞায়িত করে যে আমরা কীভাবে ডেটা পার্টিশন বা গ্রুপ করতে চাই।
নমুনা তথ্য
আসুন আমরা একটি নমুনা ডেটা সহ একটি মৌলিক সারণী তৈরি করি যা প্রদর্শন করার জন্য কীভাবে পার্টিশন বাই ক্লজ ব্যবহার করতে হয়। এই উদাহরণের জন্য, আসুন একটি মৌলিক টেবিল তৈরি করি যা পণ্যের তথ্য সংরক্ষণ করে।
টেবিল পণ্য তৈরি করুন (
পণ্য_আইডি আইএনটি প্রাথমিক কী স্বয়ংক্রিয়_INCREMENT,
পণ্য_নাম VARCHAR( 255 ),
শ্রেণী VARCHAR( 255 ),
মূল্য দশমিক( 10 , 2 ),
পরিমাণ INT,
মেয়াদ শেষ হওয়ার_তারিখ DATE,
বারকোড BIGINT
);
সন্নিবেশ
মধ্যে
পণ্য (পণ্য_নাম,
বিভাগ,
মূল্য,
পরিমাণ,
মেয়াদ শেষ হওয়ার_তারিখ,
বারকোড)
মান ( 'শেফ হ্যাট 25 সেমি' ,
'বেকারি' ,
24.67 ,
57 ,
'2023-09-09' ,
2854509564204 );
সন্নিবেশ
মধ্যে
পণ্য (পণ্য_নাম,
বিভাগ,
মূল্য,
পরিমাণ,
মেয়াদ শেষ হওয়ার_তারিখ,
বারকোড)
মান ( 'কোয়েলের ডিম - টিনজাত' ,
'প্যানট্রি' ,
17.99 ,
67 ,
'2023-09-29' ,
1708039594250 );
সন্নিবেশ
মধ্যে
পণ্য (পণ্য_নাম,
বিভাগ,
মূল্য,
পরিমাণ,
মেয়াদ শেষ হওয়ার_তারিখ,
বারকোড)
মান ( 'কফি - ডিম নগ ক্যাপুচিনো' ,
'বেকারি' ,
92.53 ,
10 ,
'2023-09-22' ,
8704051853058 );
সন্নিবেশ
মধ্যে
পণ্য (পণ্য_নাম,
বিভাগ,
মূল্য,
পরিমাণ,
মেয়াদ শেষ হওয়ার_তারিখ,
বারকোড)
মান ( 'নাশপাতি - কাঁটাযুক্ত' ,
'বেকারি' ,
65.29 ,
48 ,
'2023-08-23' ,
5174927442238 );
সন্নিবেশ
মধ্যে
পণ্য (পণ্য_নাম,
বিভাগ,
মূল্য,
পরিমাণ,
মেয়াদ শেষ হওয়ার_তারিখ,
বারকোড)
মান ( 'পাস্তা - অ্যাঞ্জেল হেয়ার' ,
'প্যানট্রি' ,
৪৮.৩৮ ,
59 ,
'2023-08-05' ,
8008123704782 );
সন্নিবেশ
মধ্যে
পণ্য (পণ্য_নাম,
বিভাগ,
মূল্য,
পরিমাণ,
মেয়াদ শেষ হওয়ার_তারিখ,
বারকোড)
মান ( 'ওয়াইন - প্রসেকো ভালডোবিয়াডেনে' ,
'উৎপাদন করা' ,
44.18 ,
3 ,
'2023-03-13' ,
6470981735653 );
সন্নিবেশ
মধ্যে
পণ্য (পণ্য_নাম,
বিভাগ,
মূল্য,
পরিমাণ,
মেয়াদ শেষ হওয়ার_তারিখ,
বারকোড)
মান ( 'পেস্ট্রি - ফ্রেঞ্চ মিনি অ্যাসোর্টেড' ,
'প্যানট্রি' ,
36.73 ,
52 ,
'2023-05-29' ,
5963886298051 );
সন্নিবেশ
মধ্যে
পণ্য (পণ্য_নাম,
বিভাগ,
মূল্য,
পরিমাণ,
মেয়াদ শেষ হওয়ার_তারিখ,
বারকোড)
মান ( 'কমলা - টিনজাত, ম্যান্ডারিন' ,
'উৎপাদন করা' ,
65.0 ,
1 ,
'2023-04-20' ,
6131761721332 );
সন্নিবেশ
মধ্যে
পণ্য (পণ্য_নাম,
বিভাগ,
মূল্য,
পরিমাণ,
মেয়াদ শেষ হওয়ার_তারিখ,
বারকোড)
মান ( 'শুয়োরের কাঁধ' ,
'উৎপাদন করা' ,
55.55 ,
73 ,
'2023-05-01' ,
9343592107125 );
সন্নিবেশ
মধ্যে
পণ্য (পণ্য_নাম,
বিভাগ,
মূল্য,
পরিমাণ,
মেয়াদ শেষ হওয়ার_তারিখ,
বারকোড)
মান ( 'ডিসি হিকিয়াগে হিরা হুবা' ,
'উৎপাদন করা' ,
56.29 ,
53 ,
'2023-04-14' ,
3354910667072 );
একবার আমাদের নমুনা ডেটা সেটআপ হয়ে গেলে, আমরা এগিয়ে যেতে পারি এবং বিভাগ দ্বারা বিভাজন ব্যবহার করতে পারি।
মৌলিক ব্যবহার
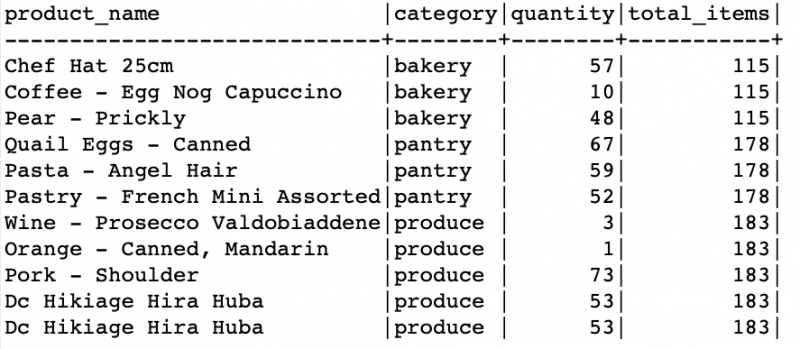
ধরুন আমরা পূর্ববর্তী টেবিলে প্রতিটি পণ্য বিভাগের জন্য মোট আইটেম গণনা করতে চাই। আমরা আইটেমগুলিকে অনন্য বিভাগে বিভক্ত করতে এবং তারপর প্রতিটি বিভাগে মোট পরিমাণ নির্ধারণ করতে PARTITION BY ব্যবহার করতে পারি।
একটি উদাহরণ নিম্নরূপ:
নির্বাচন করুন
পণ্যের নাম,
বিভাগ,
পরিমাণ,
মোট_আইটেম হিসাবে SUM(পরিমাণ) বেশি (বিভাগ অনুসারে)
থেকে
পণ্য;
লক্ষ্য করুন যে প্রদত্ত উদাহরণে, আমরা 'বিভাগ' কলাম ব্যবহার করে ডেটা বিভাজন করি। তারপর আমরা আলাদাভাবে প্রতিটি বিভাগে মোট আইটেম নির্ধারণ করতে SUM() সমষ্টি ফাংশন ব্যবহার করি। ফলাফল প্রতিটি বিভাগে মোট আইটেম দেখায়.
ধারা দ্বারা বিভাজন ব্যবহার করা
সংক্ষেপে বলতে গেলে, পার্টিশন বাই ক্লজের সবচেয়ে সাধারণ ব্যবহার হল উইন্ডো ফাংশনের সাথে। উইন্ডো ফাংশন প্রতিটি পার্টিশনে আলাদাভাবে প্রয়োগ করা হয়।
PARTITION BY এর সাথে ব্যবহার করার জন্য কিছু সাধারণ উইন্ডো ফাংশন নিম্নলিখিতগুলি অন্তর্ভুক্ত করে:
- SUM() - প্রতিটি পার্টিশনের মধ্যে একটি কলামের যোগফল গণনা করুন।
- AVG() - প্রতিটি পার্টিশনের মধ্যে একটি কলামের গড় গণনা করুন।
- COUNT() - প্রতিটি পার্টিশনের মধ্যে সারির সংখ্যা গণনা করুন।
- ROW_NUMBER() – প্রতিটি পার্টিশনের মধ্যে প্রতিটি সারিতে একটি অনন্য সারি নম্বর বরাদ্দ করুন।
- RANK() – প্রতিটি পার্টিশনের মধ্যে প্রতিটি সারিতে একটি র্যাঙ্ক বরাদ্দ করুন।
- DENSE_RANK() – প্রতিটি পার্টিশনের মধ্যে প্রতিটি সারিতে একটি ঘন র্যাঙ্ক বরাদ্দ করুন।
- NTILE() - প্রতিটি পার্টিশনের মধ্যে ডেটাকে কোয়ান্টাইলে ভাগ করুন।
এটাই!
উপসংহার
এই টিউটোরিয়ালে, আমরা শিখেছি কিভাবে SQL-এ PARTITION BY ক্লজ দিয়ে ডেটাকে বিভিন্ন সেগমেন্টে বিভাজন করতে হয় এবং তারপর প্রতিটি ফলাফলে পৃথকভাবে একটি নির্দিষ্ট অপারেশন প্রয়োগ করতে হয়।