R-এ, কলামের সংখ্যা পাওয়া একটি মৌলিক অপারেশন যা ডেটাফ্রেমের সাথে কাজ করার সময় অনেক পরিস্থিতিতে প্রয়োজন হয়। ডেটা সাবসেটিং, বিশ্লেষণ, ম্যানিপুলেট, প্রকাশ এবং ভিজ্যুয়ালাইজ করার সময়, কলামের গণনা জানার জন্য তথ্যের একটি গুরুত্বপূর্ণ অংশ। অতএব, নির্দিষ্ট ডেটাফ্রেমের মোট কলাম পেতে R বিভিন্ন পন্থা প্রদান করে। এই নিবন্ধে, আমরা কিছু পন্থা নিয়ে আলোচনা করব যা আমাদের ডেটাফ্রেমের কলামের গণনা পেতে সাহায্য করে।
উদাহরণ 1: Ncol() ফাংশন ব্যবহার করা
ncol() হল ডাটাফ্রেমের মোট কলাম পাওয়ার জন্য সবচেয়ে ঘন ঘন ফাংশন।
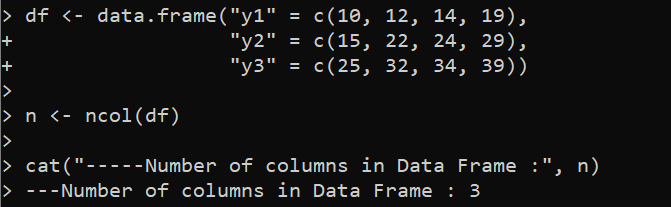
df <- data.frame('y1' = c(10, 12, 14, 19),
'y2' = c(15, 22, 24, 29),
'y3' = c(25, 32, 34, 39))
n <- ncol(df)
cat('------ডেটা ফ্রেমে কলামের সংখ্যা :', n)
এই উদাহরণে, আমরা প্রথমে তিনটি কলাম সহ একটি 'df' ডেটাফ্রেম তৈরি করি যা 'y1', 'y2', এবং 'y3' হিসাবে লেবেল করা হয় R-এ data.frame() ফাংশন ব্যবহার করে। প্রতিটি কলামের উপাদানগুলি ব্যবহার করে নির্দিষ্ট করা হয়। c() ফাংশন যা উপাদানগুলির একটি ভেক্টর তৈরি করে। তারপর, “n” ভেরিয়েবল ব্যবহার করে, ncol() ফাংশনটি “df” ডেটাফ্রেমের মোট কলাম নির্ধারণ করতে ব্যবহৃত হয়। অবশেষে, বর্ণনামূলক বার্তা এবং 'n' ভেরিয়েবল সহ, প্রদত্ত cat() ফাংশন কনসোলে ফলাফল প্রিন্ট করে।
প্রত্যাশিত হিসাবে, পুনরুদ্ধার করা আউটপুট নির্দেশ করে যে নির্দিষ্ট ডেটাফ্রেমে তিনটি কলাম রয়েছে:
উদাহরণ 2: খালি ডেটাফ্রেমের জন্য মোট কলাম গণনা করুন
এরপরে, আমরা খালি ডেটাফ্রেমে ncol() ফাংশন প্রয়োগ করি যা মোট কলামের মানও পায় কিন্তু সেই মানটি শূন্য।
empty_df <- data.frame()n <- ncol(empty_df)
cat('---ডেটা ফ্রেমের কলাম :', n)
এই উদাহরণে, আমরা কোনো কলাম বা সারি নির্দিষ্ট না করে data.frame() কল করে খালি ডেটাফ্রেম, 'empty_df' তৈরি করি। এর পরে, আমরা ncol() ফাংশনটি ব্যবহার করি যা ডেটাফ্রেমে কলামের গণনা খুঁজে পেতে ব্যবহৃত হয়। মোট কলাম পেতে ncol() ফাংশনটি এখানে “empty_df” ডেটাফ্রেমের সাথে সেট করা আছে। যেহেতু 'empty_df' DataFrame খালি, এতে কোনো কলাম নেই। সুতরাং, ncol(empty_df) এর আউটপুট হল 0। ফলাফলগুলি cat() ফাংশন দ্বারা প্রদর্শিত হয় যা এখানে স্থাপন করা হয়েছে।
আউটপুট '0' মানটি প্রত্যাশিত হিসাবে দেখায় কারণ ডেটাফ্রেম খালি।

উদাহরণ 3: Length() ফাংশনের সাথে Select_If() ফাংশন ব্যবহার করা
আমরা যদি কোনো নির্দিষ্ট ধরনের কলামের সংখ্যা পুনরুদ্ধার করতে চাই, তাহলে আমাদের R-এর length() ফাংশনের সাথে একযোগে select_if() ফাংশন ব্যবহার করা উচিত। এই ফাংশনগুলি ব্যবহার করা হয় যা প্রতিটি ধরনের কলামের মোট সংখ্যা পেতে ব্যবহার করা হয়। . এই ফাংশন ব্যবহার করার জন্য কোড নিম্নলিখিত প্রয়োগ করা হয়:
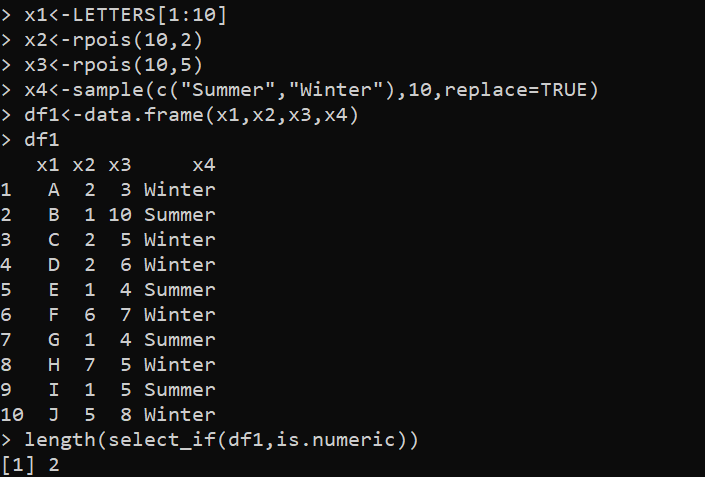
লাইব্রেরি(dplyr)x1<-অক্ষর[1:10]
x2<-rpois(10,2)
x3<-rpois(10,5)
x4<-নমুনা(c('গ্রীষ্ম','শীতকাল'),10,প্রতিস্থাপন=TRUE)
df1<-data.frame(x1,x2,x3,x4)
df1
দৈর্ঘ্য(select_if(df1,is.numeric))
এই উদাহরণে, আমরা প্রথমে dplyr প্যাকেজ লোড করি যাতে আমরা select_if() ফাংশন এবং length() ফাংশন অ্যাক্সেস করতে পারি। তারপর, আমরা চারটি ভেরিয়েবল তৈরি করি – যথাক্রমে “x1”, “x2”, “x3” এবং “x4”। এখানে, 'x1' ইংরেজি বর্ণমালার প্রথম 10টি বড় হাতের অক্ষর রয়েছে। 'x2' এবং 'x3' ভেরিয়েবলগুলি যথাক্রমে 2 এবং 5 প্যারামিটার সহ 10 র্যান্ডম সংখ্যার দুটি পৃথক ভেক্টর তৈরি করতে rpois() ফাংশন ব্যবহার করে তৈরি করা হয়। 'x4' ভেরিয়েবল হল একটি ফ্যাক্টর ভেক্টর যার 10টি উপাদান রয়েছে যা ভেক্টর c ('গ্রীষ্ম', 'শীত') থেকে এলোমেলোভাবে নমুনা করা হয়।
তারপর, আমরা 'df1' ডেটাফ্রেম তৈরি করার চেষ্টা করি যেখানে data.frame() ফাংশনে সমস্ত ভেরিয়েবল পাস করা হয়। অবশেষে, dplyr প্যাকেজ থেকে select_if() ফাংশন ব্যবহার করে তৈরি করা 'df1' ডেটাফ্রেমের দৈর্ঘ্য নির্ধারণ করতে আমরা length() ফাংশনটি ব্যবহার করি। Select_if() ফাংশন একটি আর্গুমেন্ট হিসাবে একটি “df1” ডেটাফ্রেম থেকে কলাম নির্বাচন করে এবং is.numeric() ফাংশন শুধুমাত্র সাংখ্যিক মান ধারণকারী কলাম নির্বাচন করে। তারপর, length() ফাংশন মোট কলাম পায় যা select_if() দ্বারা নির্বাচিত হয় যা পুরো কোডের আউটপুট।
কলামের দৈর্ঘ্য নিম্নলিখিত আউটপুটে দেখানো হয়েছে যা ডেটাফ্রেমের মোট কলাম নির্দেশ করে:
উদাহরণ 4: সাপ্লাই() ফাংশন ব্যবহার করা
বিপরীতভাবে, যদি আমরা শুধুমাত্র কলামের অনুপস্থিত মান গণনা করতে চাই, আমাদের কাছে saply() ফাংশন আছে। সাপ্লাই() ফাংশনটি ডেটাফ্রেমের প্রতিটি কলামে নির্দিষ্টভাবে কাজ করার জন্য পুনরাবৃত্তি করে। sapply() ফাংশনটি প্রথমে একটি আর্গুমেন্ট হিসাবে ডেটাফ্রেমের সাথে পাস করা হয়। তারপরে, সেই ডেটাফ্রেমে সঞ্চালিত হতে অপারেশন লাগে। DataFrame কলামে NA মান গণনা করার জন্য sapply() ফাংশনের বাস্তবায়ন নিম্নরূপ প্রদান করা হয়েছে:
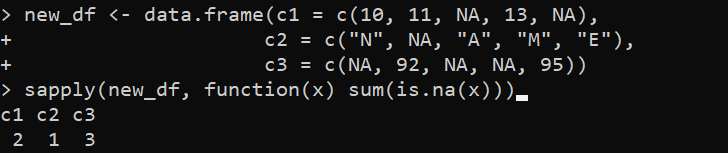
new_df <- data.frame(c1 = c(10, 11, NA, 13, NA),c2 = c('N', NA, 'A', 'M', 'E'),
c3 = c(NA, 92, NA, NA, 95))
sapply(new_df, function(x) sum(is.na(x)))
এই উদাহরণে, আমরা তিনটি কলাম সহ “new_df” ডেটাফ্রেম তৈরি করি – “c1”, “c2”, এবং “c3”। প্রথম কলাম, 'c1' এবং 'c3', কিছু অনুপস্থিত মান সহ সাংখ্যিক মান রয়েছে যা NA দ্বারা প্রতিনিধিত্ব করা হয়। দ্বিতীয় কলাম, “c2”-এ কিছু অনুপস্থিত মান সহ অক্ষর রয়েছে যা NA দ্বারাও প্রতিনিধিত্ব করে। তারপর, আমরা 'new_df' DataFrame-এ sapply() ফাংশন প্রয়োগ করি এবং sapply() ফাংশনের ভিতরে sum() এক্সপ্রেশন ব্যবহার করে প্রতিটি কলামে অনুপস্থিত মানের সংখ্যা গণনা করি।
is.na() ফাংশন হল সেই অভিব্যক্তি যা sum() ফাংশনে নির্দিষ্ট করা হয় যা একটি লজিক্যাল ভেক্টর প্রদান করে যা নির্দেশ করে যে কলামের প্রতিটি উপাদান অনুপস্থিত কিনা। sum() ফাংশন প্রতিটি কলামে অনুপস্থিত মানের সংখ্যা গণনা করতে TRUE মান যোগ করে।
সুতরাং, আউটপুট প্রতিটি কলামে মোট NA মান প্রদর্শন করে:
উদাহরণ 5: Dim() ফাংশন ব্যবহার করা
উপরন্তু, আমরা ডেটাফ্রেমের সারি সহ মোট কলাম পেতে চাই। তারপর, dim() ফাংশন ডেটাফ্রেমের মাত্রা প্রদান করে। dim() ফাংশন বস্তুটিকে একটি আর্গুমেন্ট হিসেবে নেয় যার মাত্রা আমরা পুনরুদ্ধার করতে চাই। এখানে dim() ফাংশন ব্যবহার করার কোড আছে:
d1 <- data.frame(team=c('t1', 't2', 't3', 't4'),পয়েন্ট = c(8, 10, 7, 4))
আবছা (d1)
এই উদাহরণে, আমরা প্রথমে 'd1' ডেটাফ্রেমকে সংজ্ঞায়িত করি যা data.frame() ফাংশন ব্যবহার করে তৈরি করা হয় যেখানে দুটি কলাম 'টিম' এবং 'পয়েন্ট' সেট করা হয়। এর পরে, আমরা 'd1' ডেটাফ্রেমের উপর dim() ফাংশনটি চালু করি। dim() ফাংশন ডেটাফ্রেমের সারি এবং কলামের সংখ্যা প্রদান করে। অতএব, যখন আমরা dim(d1) চালাই, তখন এটি দুটি উপাদান সহ একটি ভেক্টর প্রদান করে – যার প্রথমটি 'd1' ডেটাফ্রেমের সারির সংখ্যা প্রতিফলিত করে এবং দ্বিতীয়টি কলামের সংখ্যাকে প্রতিনিধিত্ব করে।
আউটপুট ডেটাফ্রেমের মাত্রা উপস্থাপন করে যেখানে মান '4' মোট কলাম নির্দেশ করে এবং মান '2' সারিগুলিকে প্রতিনিধিত্ব করে:

উপসংহার
আমরা এখন শিখেছি যে R-এ কলামের সংখ্যা গণনা করা একটি সহজ এবং গুরুত্বপূর্ণ অপারেশন যা ডেটাফ্রেমে করা যেতে পারে। সমস্ত ফাংশনের মধ্যে, ncol() ফাংশন সবচেয়ে সুবিধাজনক উপায়। এখন, আমরা প্রদত্ত ডেটাফ্রেম থেকে কলামের সংখ্যা পাওয়ার বিভিন্ন উপায়ের সাথে পরিচিত।